














메모리 구조
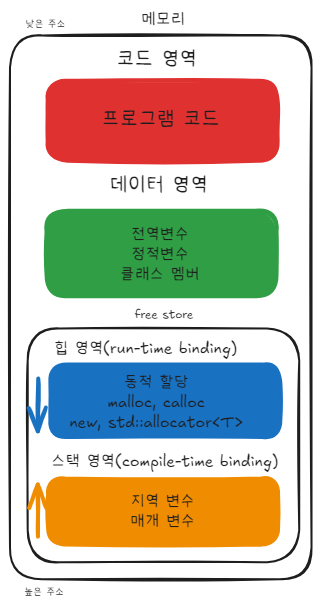
- 코드(Code) : 프로그램 소스코드 영역
- 데이터(Data) : 프로그램 시작시 할당, 종료 시 소멸되는 변수
- 힙(Heap) : 메모리 크기를 동적으로 할당하는 변수. 메모리의 해제 필수
- 스택(Stack) : 지역변수 저장
배열(array)
동일한 자료형 값을 메모리 공간에 순차적으로 여러 개 저장하여 사용하기 위한 방법.
연속적으로 만들어지기 때문에 순차적으로 접근(sequential acess), 무작위 접근(random acess) 가능하다.
<type> <name>[<value>]<value>: constant-value, variable, blank(초기화 사용 시)
- 반드시 배열을 사용해야 하는 경우가 아니라면 표준 라이브러리의 시퀀스 컨테이너(sequence container) 사용 권장
std::array<T,N>: 크기가 결정되어 있고 자료 추가가 없을 경우std::vector<T>|std::deque<T>: 동적으로 자료가 추가될 경우
#include <iostream>
#include <algorithm> // for std::copy
#include <iterator> // for std::ostream_iterator
#include <array> // for std::array
#include <vector> // for std::vector
#include <deque> // for std::deque
int main() {
int n = 5;
// 1. 정적 배열 (stack, 고정 크기)
int arr1[] = {1, 2, 3, 4, 5};
int arr1[5];
int arr1[n] = {1, 2, 3, 4, 5}; // C++에서는 n을 상수로 사용해야 함
copy(arr1, arr1 + n, std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
// 2. 동적 배열 (heap, new/delete)
int* arr2 = new int[5];
int* arr2 = new int[5]{10, 20, 30, 40, 50};
copy(arr2, arr2 + 5, std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
delete[] arr2; // 동적 메모리는 수동 해제 필요
// 3. std::array (C++11, 고정 크기 배열, stack)
std::array<int, 5> arr3 = {100, 200, 300, 400, 500};
copy(arr3.begin(), arr3.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
// 4. std::vector (가변 크기, heap 기반)
std::vector<int> arr4 = {7, 14, 21};
std::deque<int> arr4 = {7, 14, 21};
arr4.push_back(28);
copy(arr4.begin(), arr4.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << std::endl;
return 0;
}
네이티브 포인터(native pointer)
정의된 자료형의 메모리 주소를 저장하는 변수.
스마트 포인터(smart pointer) 도입 이후 C-style pointer를 네이티브 포인터(native pointer) 라고 한다.
<type>* <value><type>*: 포인터 자료형(type of pointer)<value>: 포인터(variable of pointer)- 일반적으로 포인터 자료형을 포인터라고 함
연산자(operator)
*,->,--,++,+,-,==,<,>,[]등
#include <iostream>
#include <string>
// -> 연산자 예시용 구조체
struct Person {
std::string name;
int age;
void introduce() {
std::cout << "Hi, I'm " << name << " and I'm " << age << " years old.\n";
}
};
int main() {
int arr[5] = {10, 20, 30, 40, 50};
// 1. 포인터 선언 및 주소 저장
int* p = arr; // arr == &arr[0]
std::cout << "p points to: " << *p << "\n"; // 10
// 2. 포인터 산술 연산
++p;
std::cout << "After ++p, *p = " << *p << "\n"; // 20
p += 2;
std::cout << "After p += 2, *p = " << *p << "\n"; // 40
// 3. 포인터 역참조 (*)
*p = 100; // arr[3] = 100
std::cout << "Modified arr[3]: " << arr[3] << "\n"; // 100
// 4. 포인터 비교 연산
int* p1 = &arr[1];
int* p2 = &arr[4];
if (p1 < p2) {
std::cout << "p1 points to an earlier element than p2\n";
}
// 5. 포인터 간 거리 계산
int diff = p2 - p1;
std::cout << "p2 - p1 = " << diff << " elements\n"; // 3
// 6. 배열을 포인터로 순회
std::cout << "Traverse arr using pointer (*): ";
int* ptr = arr;
for (int i = 0; i < 5; ++i) {
std::cout << *(ptr + i) << " ";
}
std::cout << "\n";
// 7. 포인터와 [] 연산자
std::cout << "Access arr using pointer and []: ";
for (int i = 0; i < 5; ++i) {
std::cout << ptr[i] << " "; // *(ptr + i) 와 동일
}
std::cout << "\n";
// 8. -> 연산자 예시
Person person = {"Alice", 25};
Person* personPtr = &person;
std::cout << "Using -> operator:\n";
std::cout << "Name: " << personPtr->name << ", Age: " << personPtr->age << "\n";
personPtr->introduce(); // 구조체 멤버 함수 호출
// (*ptr). 방식도 동일한 효과
(*personPtr).age = 26;
std::cout << "After (*personPtr).age = 26:\n";
(*personPtr).introduce();
return 0;
}
널 포인터(Null Pointer)
0,NULL,(void*)0,nullptr0의 경우 <int> 타입이며 포인터가 아니지만, null 포인터 상수로 취급
nullptr사용 권장- 명확한 pointer type
- pointer 외에 다른 타입으로의 implicit conversion 방지(int, bool 등)
| 표현 | 타입 | 설명 |
|---|---|---|
0 |
int |
null 표현으로 허용되지만 본질은 정수 |
NULL |
매크로 (0 or (void*)0) |
정의에 따라 다름, C 스타일, 위험성 존재 |
(void*)0 |
void* |
void 포인터 타입 → 타입 변환 필요 |
nullptr |
std::nullptr_t |
C++11 도입, 명확한 null 포인터 타입, 타입 안정성 ↑ |
#include <iostream>
#include <typeinfo>
using namespace std;
int main()
{
printf("%s, %lu\n", typeid(0).name(), sizeof(0));
printf("%s, %lu\n", typeid(NULL).name(), sizeof(NULL));
printf("%s, %lu\n", typeid((void*)0).name(), sizeof((void*)0));
printf("%s, %lu\n", typeid(nullptr).name(), sizeof(typeid(nullptr).name()));
}
>>>
i, 4
l, 8
Pv, 8
Dn, 8
다차원 배열
- 다차원 배열 형태로 자료를 사용할 경우, 각 자료형에 맞게 할당을 하고 모두 해제해야 함
int** pMatrix = new int[i][j]: compile error
int** pMatrix = new int*[10];
for (size_t i = 0; i < 10; i++)
pMatrix[i] = new int[10];
//... do something
for (size_t i = 0; i < 10; i++)
delete [] pMatrix[i];
delete [] pMatrix;
레퍼런스(reference)
포인터는 NULL이 될 수 있으나, 참조자는 존재하는 것만 지정 가능(alias) 하다.
이름만 대신하는 방식으로 동작하며, 일반적인 지역 변수 사용과 동일한 형태이기 때문에 사용하기 편하다.
- 지정한 변수와 동일한 주소값을 가짐
const <type>& <var>- reference는 존재하는 변수의 주소값을 받으나
const의 경우 예외적으로 rvalue를 받을 수 있음- 임시로 존재하는 객체의 값을 참조만 할 뿐, 변경이 불가(원칙상으로는)하기 때문
#include <iostream>
int& func(int &a){return a;}
int main() {
int x = 10;
int& ref = x; // Binding reference to x
int& ref = func(x); // Binding reference to the return value of func
const int& r1 = 20; // Binding a const reference to a temporary
int& r2 = 30; // error, Binding a non-const reference to a temporary
return 0;
}
- compile 후 실행은 pointer와 동일
class DataType {
int n;
double d;
};
DataType fnRef(DataType const & data) { return data; }
DataType fnPnt(DataType const * data) { return *data; }
- 편리성을 증가시키고 자원관리 문제를 해소하는 역할을 하지만
- 소유권 이전 문제가 존재(alias)
- rvalue 참조자
- 이동생성자(move constructor)와 이동대입연산자(move assignment operator)
lvalue 참조자
함수의 call by reference 기능을 지원한다.
즉 객체를 복사하지 않고 사용 가능하며, 객체 다형성 기능을 사용할 수 있다.
lvalue 참조자를 const로 정의한 경우 임시 객체를 사용할 수 있다.
void func(int& n) { do somethings...; }
void func_const(const int& n) { do somethings... }
int n = 100;
func(n); // ok
func_const(n); // ok
func(10); // error
func_const(10); // ok
- 사용자 정의 자료형의 객체를 매개변수로 사용하는 경우 참조자 사용
const <type>& <var>매개변수 사용- 객체의 값을 바꾸지 않는 경우
- 임시 객체를 사용하는 경우
#include <bits/stdc++.h>
struct DataType {
int n;
double d;
std::string str;
std::string to_string() const {
std::ostringstream oss;
oss << n << ',' << d << ',' << str;
return oss.str();
}
};
void func(DataType& data) {
std::cout << data.to_string() << '\n';
}
void func_const(const DataType& data) {
std::cout << data.to_string() << '\n';
}
int main() {
DataType Data{10, 3.14, "ABC"};
func(Data); // ok
//func(DataType{7, 0.12, "LMN"}); // error
func_const(Data); // ok, Data 유지
func_const(DataType{1, 2.18, "XYZ"}); // ok, 임시 객체
}
rvalue 참조자
자료 복사의 경우 동일한 데이터가 두 개 이상 존재하는 것을 의미한다.
데이터가 적을 시 문제가 되지 않지만 용량이 커질 경우 문제가 발생한다.
이를 피하기 위해 reference의 값을 넘겨주기 위해 사용되는 것이 rvalue 참조자다.
rvlaue 이동 생성
다른 변수로 값을 넘겨줄 때 데이터를 복사하지 않고 넘겨주는 경우를 의미한다.
<type,class 등> func(<type> &&<var>)- 임시 생성 객체
<var>의 경우 lvalue reference와 동일하게 argument의 참조를 받아옴 - 함수 내부에서 임시 생성 객체의 데이터를 다른 변수로 넘겨줄 때 데이터를 건내줌
- 임시 생성 객체
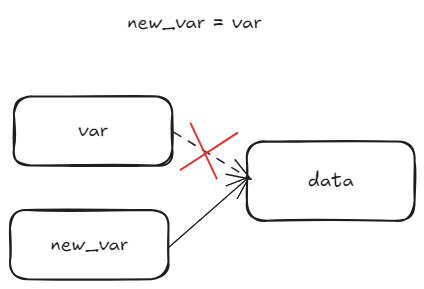
- 단, 이 과정에서
var은 데이터와 함께 삭제 권한도 함께 넘어감- 즉
new_var이 삭제(delete)될 때var도 함께 삭제 - 하지만
var과new_var은 같은 주소를 참조하고 있으므로 중복 삭제 에러 발생
- 즉
- 중복 삭제 방지
new_var = nullptr로 설정- 이후 nullptr 삭제 방지(
if (<var>) delete <var>;) new_var삭제(delete) 시var도 같이 삭제 되므로 중복 삭제 문제 해결, 안전하게 free 실행
#include <iostream>
#include <cstring>
class MyString {
private:
char* string_content;
int string_length;
public:
// 생성자
MyString(const char* str) {
string_length = std::strlen(str);
string_content = new char[string_length + 1];
std::strcpy(string_content, str);
std::cout << "생성자 호출\n";
}
// 소멸자
~MyString() {
if (string_content){
std::cout << "소멸자 호출: " << (void*)string_content << std::endl;
delete[] string_content;
}
}
// 이동 생성자
MyString(MyString&& str) {
std::cout << "이동 생성자 호출\n";
string_content = str.string_content;
string_length = str.string_length;
// str.string_content = nullptr;
}
};
int main() {
MyString a("Hello");
MyString b = std::move(a); // 이동 생성자 호출
// main 끝 → b와 a 둘 다 소멸자 호출
// 둘 다 같은 포인터에 대해 delete[] 실행 → double delete!
return 0;
}
>>>
// nullptr 미설정
생성자 호출
이동 생성자 호출
소멸자 호출: 0x7b8b20
소멸자 호출: 0x7b8b20 // 같은 주소 중복 삭제 발생, error
// nullptr 설정
생성자 호출
이동 생성자 호출
소멸자 호출: 0x7b8b20 // delete 성공, 종료
- 함수의 argument로 생성자를 입력할 시, 복사 생략(Copy elision)이 발생하며, rvalue reference를 호출
#include <iostream>
#include <vector>
template <typename T>
void wrapper(T& u) {
std::cout << "T& 로 추론됨" << std::endl;
g(u);
}
template <typename T>
void wrapper(const T& u) {
std::cout << "const T& 로 추론됨" << std::endl;
g(u);
}
class A {};
void g(A& a) { std::cout << "좌측값 레퍼런스 호출" << std::endl; }
void g(const A& a) { std::cout << "좌측값 상수 레퍼런스 호출" << std::endl; }
void g(A&& a) { std::cout << "우측값 레퍼런스 호출" << std::endl; }
int main() {
A a;
const A ca;
g(a); // 좌측값 레퍼런스 호출
g(ca); // 좌측값 상수 레퍼런스 호출
g(A()); // 우측값 레퍼런스 호출
이동 생성의 noexept
vector와 같은 컨테이너의 이동 생성 실행 시, 이동 생성자를 noexept로 명시해야 한다.
- 원소를 추가할 때, 새로운 메모리를 할당한 후에 기존에 있던 원소들을 새로운 메모리로 옮겨야 함
- 기존에 할당된 메모리보다 추가할 데이터가 클 경우
- 할당된 메모리에 최대한 복사 후,
- 복사 완료된 메모리를 해제, 초과된 데이터 복사
- 이동 생성의 경우, 이 과정에서 메모리와 함께 데이터가 함께 사라짐
- 따라서 컨테이너 타입의 경우 noexcept가 없을 시 복사 생성 실행
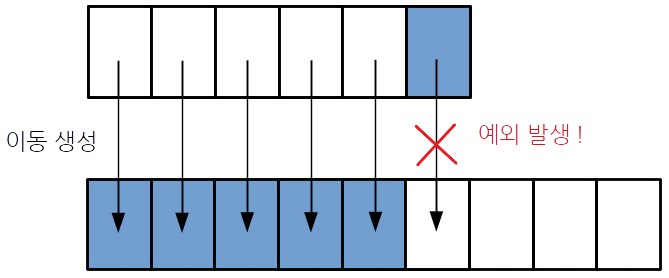
#include <iostream>
#include <cstring>
#include <vector>
class MyString {
char *string_content; // 문자열 데이터를 가리키는 포인터
int string_length; // 문자열 길이
int memory_capacity; // 현재 할당된 용량
public:
// 기본 생성자
MyString();
// 문자열로 부터 생성
MyString(const char *str);
// 복사 생성자
MyString(const MyString &str);
// 이동 생성자
MyString(MyString &&str) noexcept;
~MyString();
};
// 생성자, 복사 생성자 생략
MyString::MyString(MyString &&str) noexcept{
std::cout << "이동 생성자 호출 !" << std::endl;
string_length = str.string_length;
string_content = str.string_content;
memory_capacity = str.memory_capacity;
// 임시 객체 소멸 시에 메모리를 해제하지
// 못하게 한다.
str.string_content = nullptr;
}
MyString::~MyString() {
if (string_content) delete[] string_content;
}
int main() {
MyString s("abc");
std::vector<MyString> vec;
vec.resize(0);
std::cout << "첫 번째 추가 ---" << std::endl;
vec.push_back(s);
std::cout << "두 번째 추가 ---" << std::endl;
vec.push_back(s);
std::cout << "세 번째 추가 ---" << std::endl;
vec.push_back(s);
}
>>>
// noexept 미설정
생성자 호출 !
첫 번째 추가 ---
복사 생성자 호출 !
두 번째 추가 ---
복사 생성자 호출 !
복사 생성자 호출 !
세 번째 추가 ---
복사 생성자 호출 !
복사 생성자 호출 !
복사 생성자 호출 !
- noexept 설정 시 정상적으로 이동 생성자 호출
// noexept 설정
생성자 호출 !
첫 번째 추가 ---
복사 생성자 호출 !
두 번째 추가 ---
복사 생성자 호출 !
이동 생성자 호출 !
세 번째 추가 ---
복사 생성자 호출 !
이동 생성자 호출 !
이동 생성자 호출 !
lvalue 이동생성, Universal reference
lvalue를 인자로 사용할 경우 값을 복사하는 복사 생성을 실행한다.
rvalue를 이용한 이동 생성처럼 불필요한 복사를 삭제하기 위해 rvalue casting을 이용한다.
std::move: lvalue -> rvalue 형변환- 단순히 형변환을 실행할 뿐, 직접적인 값의 이동을 실행하진 않음
&&의 매개변수로 사용 가능
#include <iostream>
#include <utility>
class A {
public:
A() { std::cout << "일반 생성자 호출!" << std::endl; }
A(const A& a) { std::cout << "복사 생성자 호출!" << std::endl; }
A(A&& a) { std::cout << "이동 생성자 호출!" << std::endl; }
};
int main() {
A a; // 일반 생성자 호출!
A b(a); // 복사 생성자 호출!
A c(std::move(a)); // 이동 생성자 호출!
}
- 보편적 레퍼런스(universal reference)
- template의 경우 parameter가 lvalue, rvalue인지 알 수 없음
- lvalue와 rvalue 모든 경우의 수를 오버로딩하려면 경우의 수가 너무 많음
template <typename T>
void wrapper(T& u, T& v) {
g(u, v);
}
template <typename T>
void wrapper(const T& u, T& v) {
g(u, v);
}
template <typename T>
void wrapper(T& u, const T& v) {
g(u, v);
}
template <typename T>
void wrapper(const T& u, const T& v) {
g(u, v);
}
argument == &&: rvalue 오버로딩-
그 외: lvalue 오버로딩 std::forward: 매개변수로 받은 인수를 보고 적절한 자료형을 반환- template에서 rvalue reference를 받을 수 있음
#include <iostream>
template <typename T>
void wrapper(T&& u) {
g(std::forward<T>(u));
// g(u);
}
class A {};
void g(A& a) { std::cout << "좌측값 레퍼런스 호출" << std::endl; }
void g(const A& a) { std::cout << "좌측값 상수 레퍼런스 호출" << std::endl; }
void g(A&& a) { std::cout << "우측값 레퍼런스 호출" << std::endl; }
int main() {
A a;
const A ca;
wrapper(a); // 좌측값 레퍼런스 호출
wrapper(ca); // 좌측값 상수 레퍼런스 호출
wrapper(A()); // 우측값 레퍼런스 호출
// g(u); -> 좌측값 레퍼런스 호출
}
- forward 미사용
#include <iostream>
#include <vector>
template <typename T>
void wrapper(T& u) {
std::cout << "T& 로 추론됨" << std::endl;
g(u);
}
template <typename T>
void wrapper(const T& u) {
std::cout << "const T& 로 추론됨" << std::endl;
g(u);
}
class A {};
void g(A& a) { std::cout << "좌측값 레퍼런스 호출" << std::endl; }
void g(const A& a) { std::cout << "좌측값 상수 레퍼런스 호출" << std::endl; }
void g(A&& a) { std::cout << "우측값 레퍼런스 호출" << std::endl; }
int main() {
A a;
const A ca;
wrapper(a);
wrapper(ca);
wrapper(A());
}
>>>
T& 로 추론됨
좌측값 레퍼런스 호출
const T& 로 추론됨
좌측값 상수 레퍼런스 호출
const T& 로 추론됨
좌측값 상수 레퍼런스 호출
Side Effect
pass-by-reference의 경우 main과 subprogram (function, class, …)이 동일한 변수를 가진다.
따라서 프로그래밍 동작이 의도하지 않게 작동하는 경우가 발생할 수 있기 때문에 주의가 필요하다.
- 함수 호출자가 의도치 않게 영향을 받음
- 컴파일 오류나 UB이 아니기 때문에 오류를 미리 탐지할 수도 없고
- 동작을 예측하기도 어렵다(논리적 오류 발생)
- 동일 참조의 중복 전달 – Aliasing 문제
#include <iostream>
#include <iterator>
void sub(int& a, int& b) {
a = a - b;
}
int main() {
int p1 = 10;
sub(p1, p1); // 예상? => p1 = 10 - 10 = 0
std::cout << p1 << "\n"; // OK, 하지만 의미가 애매해짐
}
- 참조된 값에 영향을 주는 인덱스 변경
void sub(int& val, int& idx) {
idx = 0;
val = val + 100; // list[0]을 조작할 수도 있음
}
int main() {
int list[3] = {10, 20, 30};
int p1 = 2;
sub(list[p1], p1); // list[2]와 p1을 전달
std::copy(list, list + 3, std::ostream_iterator<int>(std::cout, " ")); // 출력: 110 20 30
// 문제는 함수 내부에서 p1 = 0으로 바꾸면
// val은 list[2]를 참조할까, list[0]을 참조할까? (UB 아님, but 모호)
}
- 루프 도중 컨테이너 구조 변경
- 매우 위험한 동작
- 설명을 위한 예시일 뿐 실제로 다음과 같이 사용하는 경우는 거의 없다(
vector 기능 놔두고 굳이..)
#include <iostream>
#include <vector>
#include <iterator>
void list_print(std::vector<int>& vec) {
size_t size = vec.size();
for (size_t i = 0; i < size; ++i) {
std::copy(vec.begin(), vec.end(), std::ostream_iterator<int>(std::cout, " "));
std::cout << "\n";
printf("vec[%zu] = %d\n", i, vec[i]);
vec.erase(vec.begin()); // 첫 번째 요소 삭제
}
}
int main() {
std::vector<int> vec = {1, 2, 3, 4, 5};
list_print(vec);
return 0;
}
>>>
1 2 3 4 5
vec[0] = 1
2 3 4 5
vec[1] = 3
3 4 5
vec[2] = 5 // UB
4 5
vec[3] = 5 // UB
5
vec[4] = 5 // UB
- 함수의 작동원리를 정확히 이해하고 사용(pass-by-value, pass-by-reference)
- 불변, 가변 데이터를 구분
- 일정한 데이터는 constant (
const|const&)로 값 고정
- 일정한 데이터는 constant (
문자, 문자 리터럴
C++의 기본 문자 리터럴의 경우 char*(C-style)이다.
일반적으로 일부 특징과 단점을 개선한 Standard Template Library (STL) 에 정의된 문자를 사용한다.
"<str>":const char*|char[]'<str>': int 타입(ASCII 코드)
auto cstr = "Hello, World!"; // C-style string
int ns = 'abc'; // <- ns 는 'abc' 의 ASCII 코드값을 저장함, 즉 97
cstr.size(); // error
/*
const char *cstr
C-style string
*/
basic_string
특정 타입의 객체들을 메모리에 연속적으로 저장하고, 여러가지 문자열 연산들을 지원해주는 클래스.
template <class CharT, class Traits = std::char_traits<CharT>,
class Allocator = std::allocator<CharT> >
class basic_string;
CharT: 객체 저장 타입
| 타입 | 정의 | 비고 |
|---|---|---|
| std::string | std::basic_string<char> |
|
| std::wstring | std::basic_string<wchar_t> |
wchar_t 의 크기는 시스템 마다 다름. 윈도우에서는 2 바이트이고, 유닉스 시스템에서는 4 바이트 |
std::u8string |
std::basic_string<char8_t> |
C++ 20 에 새로 추가되었음; char8_t 는 1 바이트; UTF-8 문자열을 보관할 수 있음 |
| std::u16string | std::basic_string<char16_t> |
char16_t 는 2 바이트; UTF-16 문자열을 보관할 수 있음 |
| std::u32string | std::basic_string<char32_t> |
char32_t 는 4 바이트; UTF-32 문자열을 보관할 수 있음 |
Traits: 기본적인 문자열 연산들을 정의- 대소 비교, 길이 등
- 간단한 연산을 제공, 데이터를 저장할 필요가 없음 -> 모두 static함수로 정의
- 원하는 기능을 Overriding을 통해 사용 가능
// 숫자와 문자열의 우선순위를 바꾸는 예시
#include <cctype>
#include <iostream>
#include <string>
// char_traits 의 모든 함수들은 static 함수 입니다.
struct my_char_traits : public std::char_traits<char> {
static int get_real_rank(char c) {
// 숫자면 순위를 엄청 떨어트린다.
if (isdigit(c)) {
return c + 256;
}
return c;
}
static bool lt(char c1, char c2) {
return get_real_rank(c1) < get_real_rank(c2);
}
static int compare(const char* s1, const char* s2, size_t n) {
while (n-- != 0) {
if (get_real_rank(*s1) < get_real_rank(*s2)) {
return -1;
}
if (get_real_rank(*s1) > get_real_rank(*s2)) {
return 1;
}
++s1;
++s2;
}
return 0;
}
};
int main() {
std::basic_string<char, my_char_traits> my_s1 = "1a";
std::basic_string<char, my_char_traits> my_s2 = "a1";
std::cout << "숫자의 우선순위가 더 낮은 문자열 : " << std::boolalpha
<< (my_s1 < my_s2) << std::endl;
// 숫자의 우선순위가 더 낮은 문자열 : false
std::string s1 = "1a";
std::string s2 = "a1";
std::cout << "일반 문자열 : " << std::boolalpha << (s1 < s2) << std::endl;
// 일반 문자열 : true
}
문자 리터럴
기본 문자 리터럴은 C-style이지만,
std::literals를 이용해 C++-style 문자 리터럴 사용이 가능하다.
using namespace std::literals: namespace 선언 필요<string>s: std::stringL<string>: std::wstring
using namespace std::string_literals; // for string literals
int main() {
auto cstr = "Hello, World!"; // C-style string
auto str = "Hello, World!"s; // C++ string literal
auto wstr = L"Hello, World!"; // Wide string literal
auto multistr = R"({}H
e
l
l
o, World!)";
}
string_view
문자열을 변경하지 않고 읽기만 하고 싶을 경우 사용한다.
C++에서는 문자 리터럴이 C-style (pointer), C++-style (reference) 2가지 다른 방식이 존재하기 때문에, 항상 2가지 방법의 overloading이 필요하다.
2가지 버전에 상관없이 일반적으로 처리하기 위해 사용하는 것이 string_view 타입이다.
- 인자의 형태
const stirng&:const char*일 경우 string 객체 생성(복사 발생)const char*: 주소값 처리(pointer), 길이 정보 매번 계산 필요
#include <iostream>
#include <string>
void* operator new(std::size_t count) {
std::cout << count << " bytes 할당 " << std::endl;
return malloc(count);
}
// 문자열에 "very" 라는 단어가 있으면 true 를 리턴함
bool contains_very(const std::string& str) {
return str.find("very") != std::string::npos;
}
int main() {
// 암묵적으로 std::string 객체가 불필요하게 생성된다.
std::cout << std::boolalpha << contains_very("c++ string is very easy to use")
<< std::endl;
std::cout << contains_very("c++ string is not easy to use") << std::endl;
}
>>>
31 bytes 할당
true
30 bytes 할당
false
string_view: 읽기 전용 타입- 문자열을 소유하지 않기 때문에 소멸 상태인지 확인 필요(UB, 함수 return 등)
- O(1) 로 매우 빠르게 수행
#include <iostream>
#include <string>
void* operator new(std::size_t count) {
std::cout << count << " bytes 할당 " << std::endl;
return malloc(count);
}
// 문자열에 "very" 라는 단어가 있으면 true 를 리턴함
bool contains_very(std::string_view str) {
return str.find("very") != std::string_view::npos;
}
int main() {
// string_view 생성 시에는 메모리 할당이 필요 없다.
std::cout << std::boolalpha << contains_very("c++ string is very easy to use")
<< std::endl;
std::cout << contains_very("c++ string is not easy to use") << std::endl;
std::string str = "some long long long long long string";
std::cout << "--------------------" << std::endl;
std::cout << contains_very(str) << std::endl;
}
>>>
true
false
37 bytes 할당
--------------------
false
#include <iostream>
#include <string>
std::string_view return_sv() {
std::string s = "this is a string";
std::string_view sv = s;
return sv;
}
int main() {
std::string_view sv = return_sv(); // <- sv 가 가리키는 s 는 이미 소멸됨!
// Undefined behavior!!!!
std::cout << sv << std::endl; // z0z, oo 등
}
std::stirng 함수
특정 원소 접근
| 함수 | 설명 |
|---|---|
| str.at(idx) | idx 위치 문자 반환, 범위 유효성 체크 O |
| str[idx] | idx 위치 문자 반환, 범위 유효성 체크 X |
| str.front() | 문자열의 가장 앞의 문자 반환 |
| str.back() | 문자열의 가장 뒤의 문자 반환 |
문자열의 크기
| 함수 | 설명 |
|---|---|
| str.length() | 문자열 길이 반환 |
| str.size() | 문자열 길이 반환(length()와 동일) |
| str.max_size() | 최대한 메모리 할당할 경우 저장할 수 있는 문자열 길이 반환 |
| str.capacity() | 문자열의 메모리 크기 반환 |
| str.resize(n) | str을 n의 크기로 만듦. 삭제 또는 빈 공간으로 채움 |
| str.resize(n, ‘a’) | n이 str 길이보다 크면 빈 공간을 ‘a’로 채움 |
| str.shrink_to_fit() | capacity가 실제 사용하는 메모리보다 큰 경우 메모리 줄여 줌(메모리 낭비 제거) |
| str.reserve(n) | 사이즈 n 만큼의 메모리 미리 할당 |
| str.empty() | str이 빈 문자열인지 확인 |
문자열 삽입/추가/삭제
| 함수 | 설명 |
|---|---|
| str.append(str2) | str 뒤에 str2 문자열을 이어 붙여 줌(str + str2 와 같음) |
| str.append(str2, n ,m) | str 뒤에 ‘str2의 n index 부터 m개의 문자’를 이어 붙여 줌 |
| str.append(n, ‘a’) | str 뒤에 n 개의 ‘a’를 붙여 줌 |
| str.insert(n, str2) | n번째 index 앞에 str2 문자열을 삽입함 |
| str.replace(n, k, str2) | n번째 index 부터 k개의 문자열을 str2로 대체함 |
| str.clear() | 저장된 문자열을 모두 지움 |
| str.erase() | clear()와 같음 |
| str.erase(n, m) | n번째 index부터 m개의 문자를 지움 |
| str.erase(n, m) ← iterator | n~m index 문자열을 지움(n, m은 iterator임) |
| str.push_back(c) | str의 맨 뒤에 c를 붙여 줌 |
| str.pop_back() | str의 맨 뒤의 문자를 제거 |
| str.assign(str2) | str 에 str2 문자열을 할당함 |
부분 문자/비교/복사/찾기
| 함수 | 설명 |
|---|---|
| str.substr() | str 전체를 반환 |
| str.substr(n) | str의 n번째 index부터 끝까지 부분 문자열 반환 |
| str.substr(n, k) | str의 n번째 index부터 k개의 부분 문자열 반환 |
| str.compare(str2) | str과 str2가 같은지 비교, str<str2인 경우 음수, str>str2인 경우 양수 반환 |
| str.copy(str2, k, n) | str의 n번째 index부터 k개의 문자열 복사 |
| str.find(“abcd”) | “abcd”가 str에 포함되어 있는지 확인, 찾으면 해당 부분 첫 index 반환 |
| str.find(“abcd”, n) | n번째 index부터 “abcd”를 찾음 |
| str.find_first_of(“/”) | ”/”가 처음 나타나는 index |
| str.find_last_of(“/”) | ”/”가 마지막으로 나타나는 index |
기타
| 함수 | 설명 |
|---|---|
| str.c_str() | string을 c스타일의 문자열로 변경 |
| str.begin() | string의 시작 iterator 반환 |
| str.end() | string의 끝 iterator 반환 |
| swap(str, str2) | str과 str2를 바꿔줌 |
| str = str2 + str3 | str2와 str3를 붙여서 str에 복사함 |
| str += str2 | str 뒤에 str2를 붙여줌 |
| str = str2 | str에 str2 복사 (Deep Copy) |
| str == str2 | str과 str2가 같은지 확인 |
| str > str2, str < str2 | str이 str2보다 사전순으로 앞인지 뒤인지 확인 |
| isdigit(c) | #include |
| isalpha(c) | #include |
| toupper(c) | #include |
| tolower(c) | #include |
| stoi(), stof(), stol(), stod() | 문자열을 숫자로 변환(int, float, long, double) |
| to_string(n) | 숫자 n을 문자열로 변환 |



C
Contents