














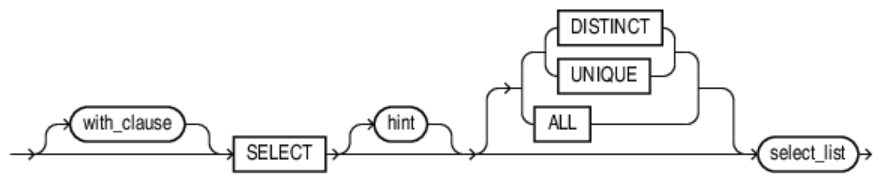
SQL
- Stuctured Query Language
- 정형 데이터 구조로 정보를 조회 및 변경의 처리를 수행하는 명령어
- TABLE 형태로 저장
- 타입
- 숫자(NUMBER), 문자(VARCHAR), 날짜(DATE)
주요 특징
- 관계형 DBMS에 접근하는 유일한 언어
- ANSI/ISO-SQL
- 미국 산업 표준화 기구 (ANSI: American National Standards Institute)
- 모든 DBMS 문법이 거의 비슷 Ex) SQL-86 , SQL-89, SQL:1999 , SQL:2008, SQL:2011, SQL:2016
- English-Like
- SQL 명령어의 문법적인 구조 및 의미
- SQL 명령어는 대-소문자를 구분하지 않는다 (Case-Insensitive)
- 단 data - Case-sensitive
SELECT * FROM empwhere job = 'PRESIDENT';
SELECT * FROM emPwhere job = 'PRESIDENT';
SELECT * FROM EMP WHERE JOB = 'PRESIDENT';
SELECT * FROM empwhere job = ‘PRESIDENT’;
SELECT * FROM empwhere job = ‘president’; # 다름
- 비절차적 언어 (Non-Procedural Language)
- 구조적(Structured) & 집합적(Set-based) & 선언적(Declarative)
- request(what) → server(how)
dataset
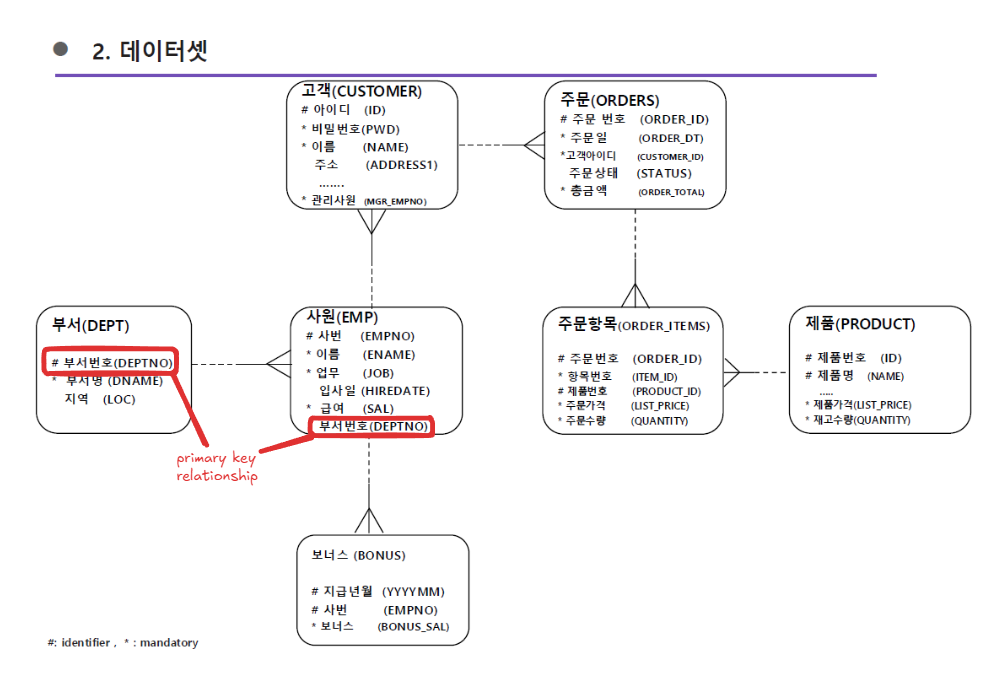
- ERD(Entity Relationship Diagram)
- attribute relation
- table 간의 관계 : primary key 공유
Command
| 분류 | 대상 | 구문 |
|---|---|---|
| Query | 데이터 | SELECT(조회) |
| DML(Data Manipulation Language) | 데이터 | INSERT(입력), UPDATE(수정), DELETE(삭제), MERGE(INSERT+UPDATE) |
| TCL(Transaction Control Language) | 트랜잭션 | COMMIT(저장), ROLLBACK(취소), SAVEPOINT(중간 저장점) |
| DDL(Data Definition Language) | Object | CREATE(생성), ALTER(변경), DROP(Object 삭제), TRUNCATE(절삭) |
| DCL(Data Control Language) | 권한 | GRANT(부여), REVOKE(취소) |
- Query(SELECT) : 정보 조회
- DML : modify data
- TCL
- COMMIT&ROLLBACK : 실행 재확인(수락하시겠습니까?)
- DCL : 접근 권한 설정
- null, space(공백) 등 data 포함
SELECT
- 정렬
- 정수 : 우측 정렬
- 문자/날짜 : 좌측 정렬
- 연산(산술, 논리, 함수, 날짜 등) 가능
- DB 연산 처리 효율↑
- 연산자 overloading(날짜 등)
- 연산자 우선순위
- ( ) > NOT > 비교연산자> SQL연산자 > AND > OR > 산술연산자
- AND, OR 연산자 우선순위 주의
SELECT [columns] FROM [TABLE];- columns :
,구분
- columns :
Alias
SELECT [columns], [[column] as [alias]], ..., FROM TABLE: Column Alias, Column Heading(lable)[[column] as [alias]]: column, alias 1:1 대응as,"alias names",공백""사용 시 공백, 특수문자 지정 가능as사용 권장
SELECT ENAME, SAL+12, SAL*12 as annual_salary FROM EMP;
SELECT ENAME, MGR Manager,SAL*12 as annual_SAL,COMM+300 "Special Bonus" FROM EMP;
-- 컬럼 Alias3가지 표현방식(공백문자, AS,“~”)중 가장 명료한 방식은?
, “~”은 특수문자,공백문자,대소문자 구분이 필요한 경우 사용
SELECT ENAME, COMM+300 보너스, COMM+300 AS "Special Bonus" FROM EMP;
문자열 결합 연산자(||)
||- ‘’’ → ‘
- implicit conversion 지원
- explicit conversion(to varchar)
- 숫자 ↔ 날짜 conversion 미지원, $\because$ 날짜, 숫자 타입, 연산 유사
to_char(...),to_number(...),to_date(...)
SELECT ENAME||JOB FROM EMP;
-- | : 수직선 기호(Vertical bar), 파이프 문자 , OR 연산
SELECT DNAME||' 부서는'||LOC||' 지역에 위치합니다.' as LOC FROM DEPT;
-- ACCOUNTING 부서는NEW YORK 지역에 위치합니다.
-- 명목형 자료를 문장으로
SELECT ename||'''s JOB is '||job as job_list FROM emp;
-- SMITH's JOB is CLERK
-- 홑따옴표(') = 단일인용부호 = single quotation mark
-- Oracle DBMS 문자 데이터 표현 : 'Happy New Year'
-- SCOTT'sJOB is ANALYST vs SCOTT"sJOB is ANALYST
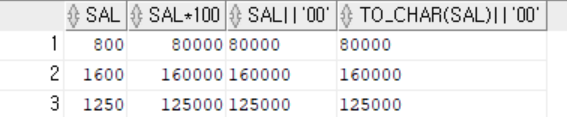
SELECT sal, sal*100, sal|| '00', to_char(sal)||'00' FROM EMP;
-- sal||'00' : 숫자 타입과 문자타입 결합, 결과 타입은?
-- Data type Conversion
Implicit Conversion(암시적, 자동으로) ex) sal|| '00'
Explicit Conversion(명시적, 수동으로) ex) to_char(sal) || '00'
-- 좋은방식의 SQL Coding은?
DUAL
sys(DBMS server) 계정 소유의 Dummy Table(실제 table x)로 function, calculation을 수행하기 위한 1x1 size table
- local 기준이 아닌 DBMS server 기준
- sysdate : system의 현재 date(날짜 + 시간)
- 연산의 효율
- 시간 기준 통일
- data를 조회하는게 아닌 DBMS 연산을 수행
- DBMS에 접근하기 위해서 query문 사용
- 숫자를
,로 구분 가능- type : varchar
- 자릿수 지정 가능
desc dual
SELECT * FROM DUAL;
-- DUMMY
-- X
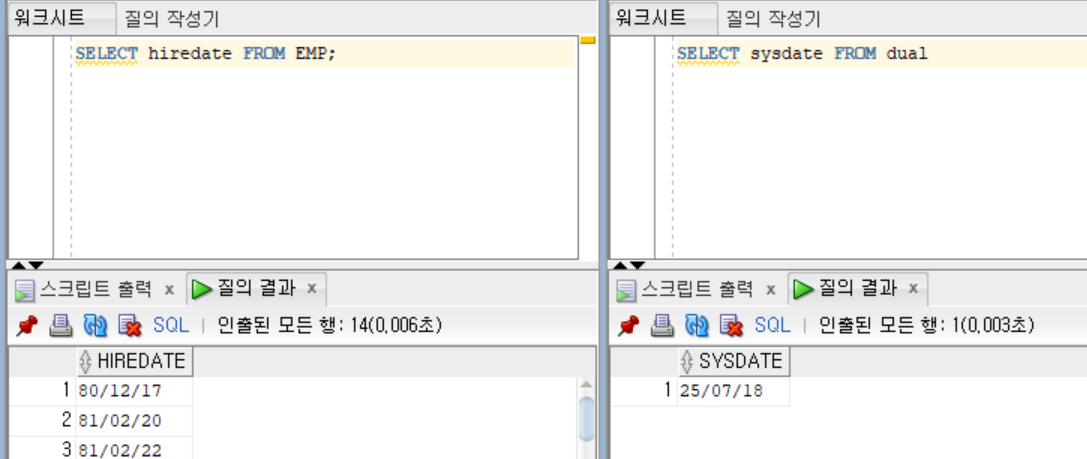
SELECT sysdate FROM dual; // system의 현재 date(날짜와 시간)을리턴하는 함수
-- SYSDATE
-- 25/07/18
--
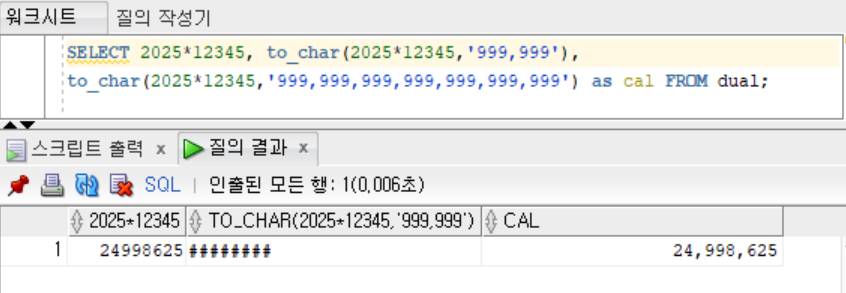
SELECT 2025*12345, to_char(2025*12345,'999,999,999'),
to_char(2025*12345,'999,999,999') as cal FROM dual;
SELECT 2025*12345, to_char(2025*12345,'999,999'),
to_char(2025*12345,'999,999,999,999,999') as cal FROM dual;
날짜 FORMAT
- FORMAT : date 표현 방식을 정의
to_date('date_str', 'format'): return date 형식의 datato_char([date_data], 'format'): return string 형식의 data
| 형식 | 의미 | 예시 입력 | 변환 결과 | 특징 |
|---|---|---|---|---|
YYYY |
4자리 연도 | '1981/02/20' |
1981년 | 정확한 4자리 연도 |
YY |
2자리 연도 | '81/02/20' |
2081년 (주의) | 현재 세기를 기준으로 계산 |
RR |
2자리 연도 | '81/02/20' |
1981년 (스마트 해석) | 1950~2049 범위 내 자동 추론 |
MM |
월 (Month) | '1981/02/20' |
2월 | 항상 2자리 |
MON |
월 약어 | '1981/FEB/20' |
FEB | 영문 약자 (대소문자 민감) |
MONTH |
월 전체 | '1981/FEBRUARY/20' |
FEBRUARY | 공백 포함, 오른쪽 정렬 가능 |
DD |
일 (Day) | '1981/02/20' |
20일 | 2자리 정수 |
DY |
요일 약어 | '1981/02/20' |
FRI | 요일 약자 (영문) |
DAY |
요일 전체 | '1981/02/20' |
FRIDAY | 공백 포함, 오른쪽 정렬 가능 |
HH24 |
24시간제 시 | '13:30' |
13 | 오후 1시 |
MI |
분 (Minute) | '13:30' |
30 | 0~59 |
- FX (format exact) :
'fx...'정확한 형식 지정
SELECT TO_CHAR(TO_DATE('0207','MM/YY'), 'MM/YY') FROM DUAL;
SELECT TO_CHAR (TO_DATE('02#07','MM/YY'), 'MM/YY') FROM DUAL;
SELECT TO_CHAR(TO_DATE('02/07', 'fxmm/yy'), 'mm/yy') FROM DUAL;
TO_CH
-----
02/07
SELECT TO_CHAR(TO_DATE('0207', 'fxmm/yy'), 'mm/yy') FROM DUAL;
SELECT TO_CHAR(TO_DATE('0207', 'fxmm/yy'), 'mm/yy') FROM DUAL;
*
ERROR at line 1:
ORA-01861: literal does not match format string
yy: 현재 연도 앞자리 + 입력 연도rr:yy보다 일반적인 연도 계산
| 현재 연도 끝 2자리 | 00~49 입력 시 앞 2자리 | 50~99 입력 시 앞 2자리 |
|---|---|---|
| 00~49 | 현재 연도 | 현재 연도 - 1 |
| 50~99 | 현재 연도 - 1 | 현재 연도 |
SELECT TO_CHAR(TO_DATE('27-OCT-98', 'DD-MON-YY'), 'YYYY') "Year" FROM DUAL;
Year
----
2098
SELECT TO_CHAR(TO_DATE('27-OCT-98', 'DD-MON-RR'), 'YYYY') "Year" FROM DUAL;
Year
----
1998
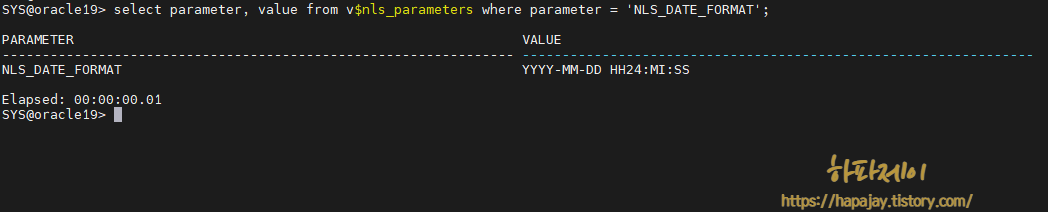
- NLS_DATE_FORMAT : format의 기본 형식
- NLS_DATE_FORMAT = “MM/DD/YYYY”(oracle)

alter session set nls_date_format ='format': 날짜 기본 형식 변경- 단 현재 실행(session) 이후 초기화

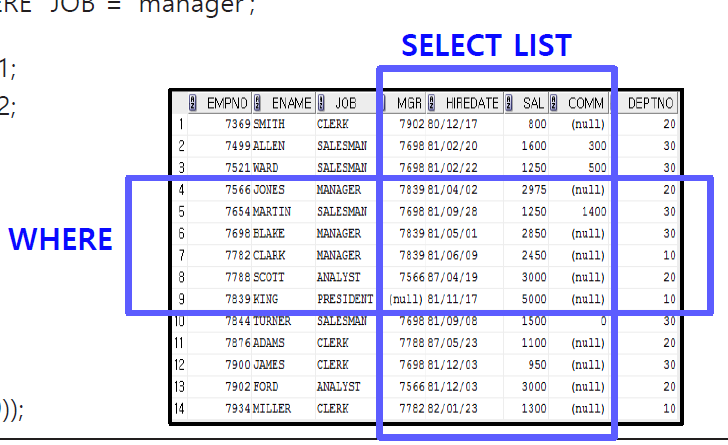
WHERE
row(record) 조회하는 조건절
- sort-circuit : X
([data]): single data(([data])): 1:1 대응
SELECT * FROM EMP WHERE DEPTNO = 10;
SELECT DEPTNO, ENAME, SAL, JOB FROM EMP WHERE SAL > 2000;
SELECT DEPTNO, ENAME, SAL, JOB FROM EMP WHERE DEPTNO = 10 AND SAL > 2000;
SELECT DEPTNO, ENAME, SAL, JOB FROM EMP WHERE DEPTNO = 10 OR SAL > 2000;
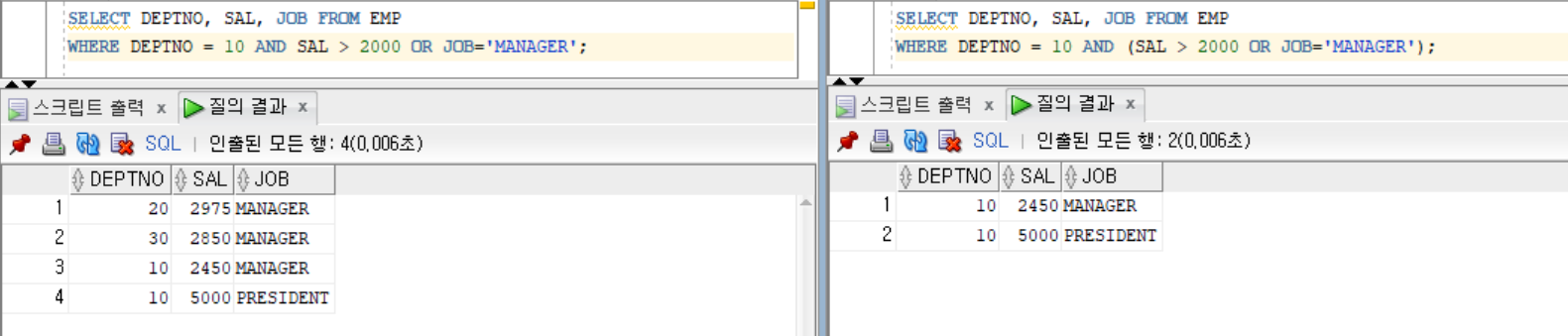
SELECT DEPTNO, SAL, JOB FROM EMP WHERE DEPTNO = 10 AND SAL > 2000 OR JOB='MANAGER';
SELECT DEPTNO, SAL, JOB FROM EMP WHERE (DEPTNO = 10 AND SAL > 2000) OR JOB='MANAGER';
-- AND > OR -> 동일
SELECT DEPTNO, SAL, JOB FROM EMP WHERE DEPTNO = 10 AND (SAL > 2000 OR JOB='MANAGER');
-- 연산자 우선순위 ? , 좋은 방식의 SQL 코딩?
SELECT DEPTNO, ENAME, SAL, JOB FROM EMP WHERE JOB = 'manager';
-- none, data case-sesitive
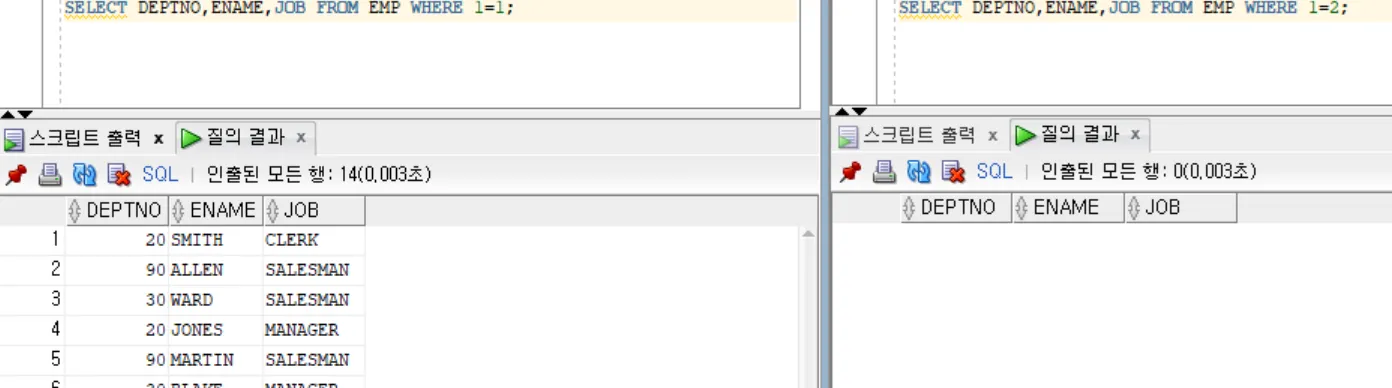
SELECT DEPTNO,ENAME,JOB FROM EMP WHERE 1=1;
SELECT DEPTNO,ENAME,JOB FROM EMP WHERE 1=2;
-- 1=1 : True, 1=2 : False
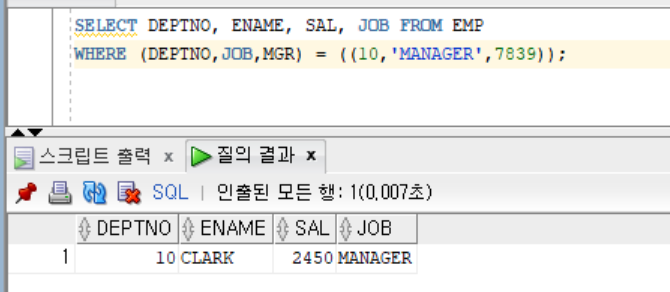
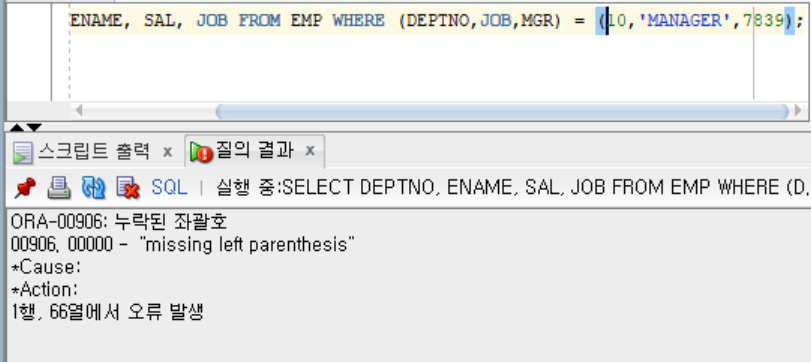
SELECT DEPTNO, ENAME, SAL, JOB FROM EMP WHERE (DEPTNO,JOB,MGR) = ((10,'MANAGER',7839));
NULL
데이터가 존재(미입력)하지 않는 상태, 결측치(Missing Value) 프로그램에 따라 공백 혹은 null data return. 제어, 비교, 연산 불가
- 0 또는 공백(black space)과 다른 데이터
- 참고 : 0(48), ‘ ‘(32), null(00)
is: null type 비교
- 연산불가
-- 연산불가
SELECT 300/0 FROM dual; // “divisor is equal to zero"
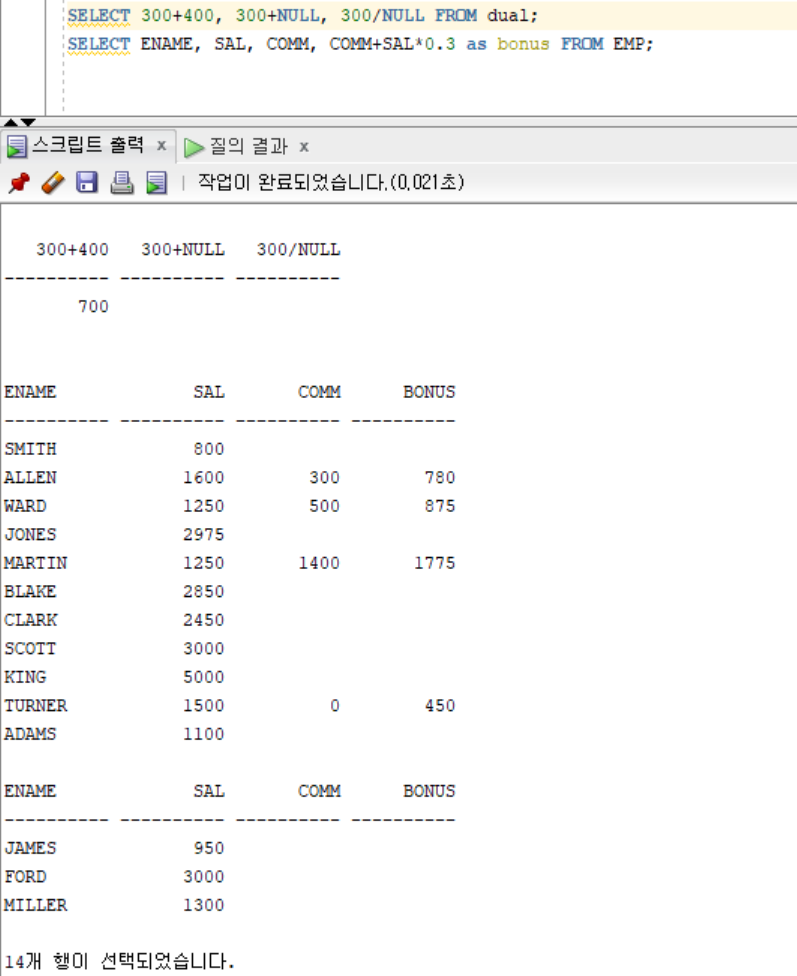
SELECT 300+400, 300+NULL, 300/NULL FROM dual; // NULL 연산 결과는?
SELECT ENAME, SAL, COMM, COMM+SAL*0.3 as bonus FROM EMP; // 실수하기 쉬운…해결책은….?
- 비교불가
-- 비교불가
SELECT ENAME,SAL,COMM FROM EMP WHERE COMM > -1; // null이 있는column 비교연산
SELECT ENAME,SAL,COMM FROM EMP WHERE COMM = null;
SELECT ENAME,SAL,COMM FROM EMP WHERE COMM <> null;
SELECT ENAME,SAL,COMM FROM EMP WHERE COMM is null;
SELECT ENAME,SAL,COMM FROM EMP WHERE COMM is not null;
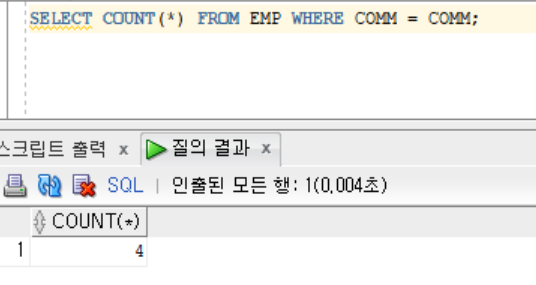
- 제어불가(함수에 적용 불가)
-- COMM : null data 포함 table
SELECT ENAME, length(ENAME), COMM, length(COMM) FROM EMP;
SELECT sal, comm, abs(sal-comm)+300 FROM emp;
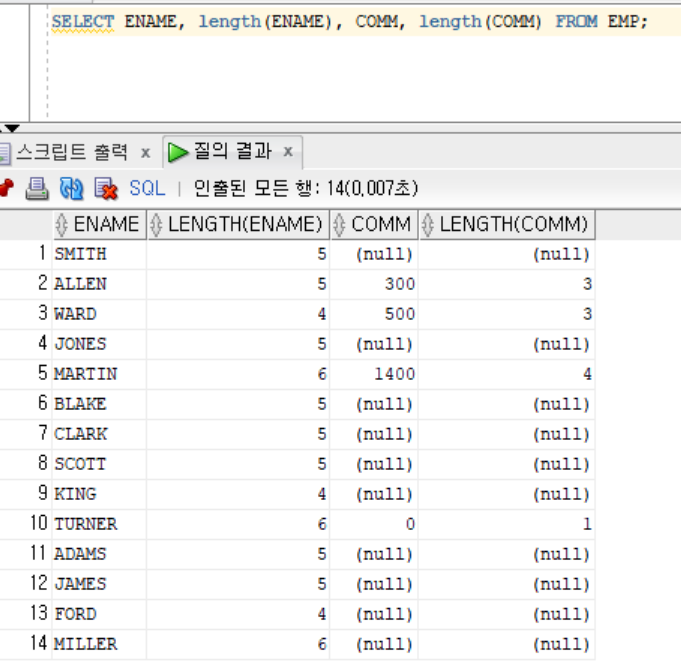
NULL 제어 함수
NVL(column, value):column상 data의 null → valueDECODE(column, compare, true_value, false_value): sql상의 if 조건문column == compare ? true_value : false_value
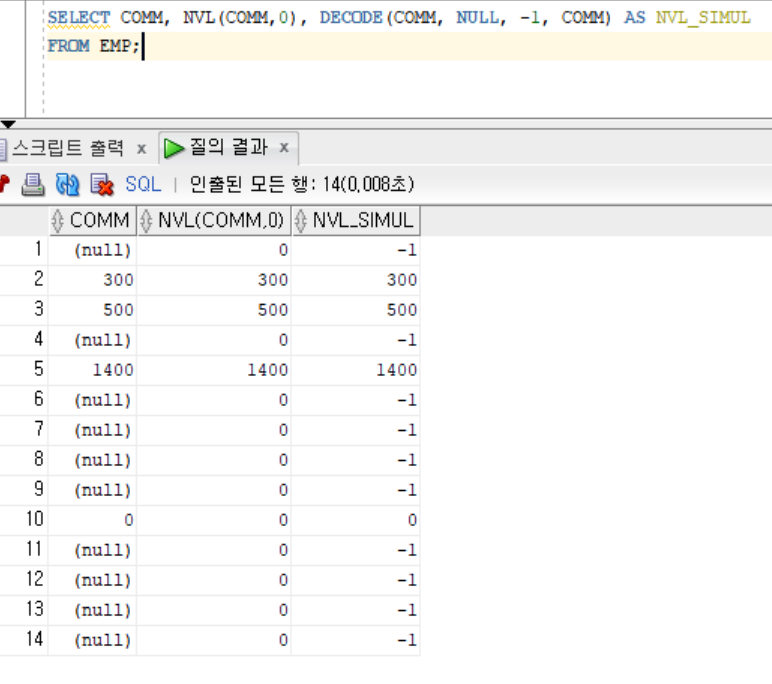
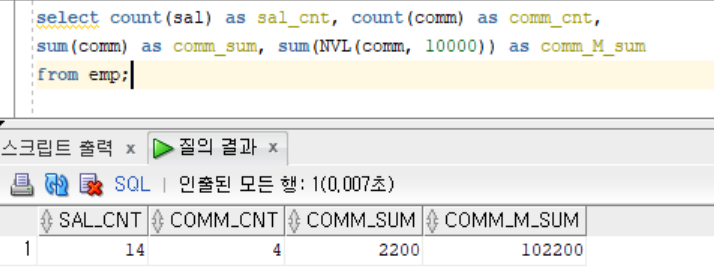
count(column): null을 제외한 column의 data 개수sum(column): null을 제외한 data의 합
SELECT COMM, NVL(COMM,0), DECODE(COMM, NULL, 0, COMM) AS NVL_SIMUL FROM EMP;
SELECT concat('Commission is ',COMM), 'Commission is '||COMM FROM EMP;--NULL 무시
select count(sal) as sal_cnt, count(comm) as comm_cnt, sum(comm) as comm_sumfrom emp;
-- 단일행 함수(Single Row Function) ex) length, abs
-- 그룹행 함수(Group Row Function) ex) count, sum
ORDER BY
sort by column
ASC: ascenging order, DEFAULTDESC: descending order
SELECT ENAME, HIREDATE, SAL, COMM FROM EMP ORDER BY ENAME ; // 정렬방향? Default
SELECT ENAME, HIREDATE, SAL, COMM FROM EMP ORDER BY ENAME asc; // SQL 가독성
SELECT ENAME, HIREDATE, SAL, COMM FROM EMP ORDER BY HIREDATE desc; // 날짜
SELECT ENAME, HIREDATE, SAL, COMM FROM EMP ORDER BY ENAME; // column name
SELECT ENAME, HIREDATE, SAL, COMM FROM EMP ORDER BY 2; // column position
SELECT ENAME, SAL*12 as 연봉 FROM EMP ORDER BY 연봉; // column alias
SELECT ENAME, HIREDATE, SAL, COMM FROM EMP ORDER BY COMM * 12; // expression, NULL 위치
SELECT ENAME, HIREDATE, SAL, COMM FROM EMP ORDER BY COMM * 12 NULLS FIRST;
SELECT DEPTNO,JOB,ENAME FROM EMP ORDER BY DEPTNO;
SELECT DEPTNO,JOB,ENAME FROM EMP ORDER BY DEPTNO,JOB; // 조합의 순서쌍
SELECT DEPTNO,JOB,ENAME FROM EMP ORDER BY DEPTNO,JOB desc; // 차이점은?
DISTINCT
중복된 데이터를 필터링하여 조회(SELECT)
DISTINT,UNIQUE
SELECT JOB FROM EMP;//Row개수 만큼,
SELECT UNIQUE JOB FROM EMP;//직군 종류,Oracle
SELECT DISTINCT JOB FROM EMP;//ANSI
- 조합 가능
SELECT DISTINCT DEPTNO,JOB FROM EMP;//중복 데이터(?)
-- 컬럼(들)의 조합의 중복 필터링
SELECT JOB FROM EMP ORDER BY JOB;
-- distinct연산 내부 알고리즘: Oracle9i:Sort,10g:Hash
- 순차 실행
SELECT DISTINCT JOB,DISTINCT DEPTNO FROM EMP;//error, 범위?
SELECT JOB, DISTINCT DEPTNO FROM EMP;//error, 위치?
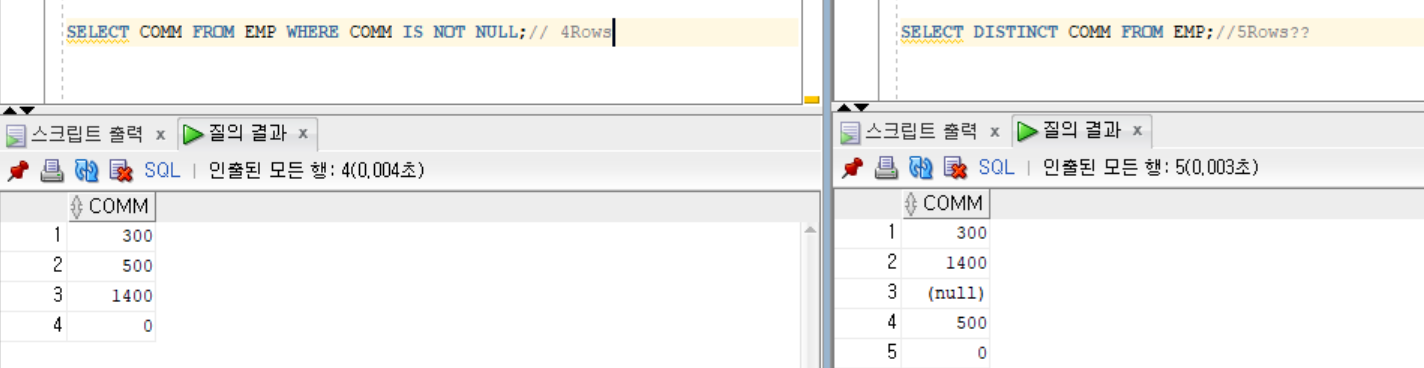
SELECT COMM FROM EMP WHERE COMMIS NOT NULL;// 4Rows
SELECT DISTINCT COMM FROM EMP;//5Rows??
-- **NULL과 DISTINCT
SQL 연산자
sql 고유 연산자
BETWEEN
하한값 - 상한값 사이의 범위 검색 연산자
SELECT ENAME,SAL,HIREDATE FROM EMP WHERE SAL between 1000 and 2000; // 숫자타입
SELECT ENAME,SAL,HIREDATE FROM EMP WHERE SAL >= 1000 and SAL <= 2000; // 차이점?
SELECT ENAME,SAL,HIREDATE FROM EMP WHERE SAL between 2000 and 1000; // 이유는?
SELECT ENAME,SAL,HIREDATE FROM EMP WHERE ENAME BETWEEN 'C' AND 'K’; -- 문자 타입
SELECT ENAME,SAL,HIREDATE FROM EMP
WHERE HIREDATE BETWEEN '81/02/20' AND '82/12/09’; // 날짜 타입, 형변환
'yy/mm/dd'→'yyyy/mm/dd'
SELECT ENAME,SAL,HIREDATE FROM EMP
WHERE HIREDATE
BETWEEN to_date('81/02/20','yy/mm/dd') AND to_date('82/12/09','yy/mm/dd');
// 날짜 타입, 명시적형변환, 검색이 안되는 이유는 ?
SELECT ENAME,HIREDATE,
TO_CHAR(HIREDATE,'YYYY/MM/DD'),
TO_CHAR(HIREDATE,'YYYY/MM/DD HH24:MI:SS'), // Date에서 시간정보확인
TO_CHAR(HIREDATE,'RRRR/MM/DD HH24:MI:SS'),
TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS')// sysdate에서 시간정보확인
FROM EMP;
SELECT ENAME,SAL,HIREDATE FROM EMP
WHERE HIREDATE
BETWEEN to_date('81/02/20', 'rr/mm/dd') AND to_date('82/12/09', 'yy/mm/dd');
SELECT ENAME,SAL,HIREDATE FROM EMP
WHERE HIREDATE
BETWEEN to_date('1981/02/20','yyyy/mm/dd') AND to_date('1982/12/09','yyyy/mm/dd');
SELECT ENAME,SAL,HIREDATE FROM EMP
WHERE HIREDATE
BETWEEN to_date('2081/02/20','yyyy/mm/dd') AND to_date('2082/12/09','yyyy/mm/dd');
LIKE
$\sim$정규표현식, 문자열 적용
- char conversion
- rvalue explicit conversion 효율적
- wildcard
%: 0개 이상(*)_: 1개 (?)
SELECT ENAME FROM EMP WHERE ENAME like 'A%'; // pattern matching
SELECT ENAME FROM EMP WHERE ENAME like '_A%';
SELECT ENAME FROM EMP WHERE ENAME like '%L%E%';
SELECT ENAME FROM EMP WHERE ENAME like '%LE%';
SELECT ENAME FROM EMP WHERE ENAME like '%A%';
SELECT ENAME FROM EMP WHERE ENAME NOT like '%A%';
SELECT ENAME,HIREDATE FROM EMP WHERE HIREDATE like '81%'; // 날짜 , 암시적 형변환
SELECT ENAME,SAL FROM EMP WHERE SAL like 2%; // error, 숫자
SELECT ENAME,SAL FROM EMP WHERE SAL like '2%'; // 암시적 형변환
SELECT ENAME,SAL FROM EMP WHERE TO_CHAR(SAL) like '2%'; // 명시적 형변환
IN
list operator
- python in과 유사
SELECT EMPNO, JOB FROM EMP WHERE EMPNO IN (7369,7521,7654);// 숫자
SELECT EMPNO, JOB FROM EMP
WHERE EMPNO = 7369 or EMPNO = 7521 or EMPNO=7654; // 차이점 ?
SELECT EMPNO,ENAME,JOB FROM EMP WHERE JOB IN ('clerk','manager'); // 문자
SELECT EMPNO,ENAME,HIREDATE FROM EMP
WHERE HIREDATE IN ('81/05/01','81/02/20'); // x, yyyy 형식
SELECT EMPNO,ENAME,JOB,DEPTNO FROM EMP
WHERE (JOB,DEPTNO) in (('MANAGER',20),('CLERK',20));// 다중컬럼리스트, in (1..1000)
- ANY, ALL
DECODE, CASE
DECODE
- 조건절(if ~ else if ~ else) 연산자
=비교 연산자만 사용

SELECT DEPTNO, ENAME, DECODE(DEPTNO,10,'ACCOUNTING',20,'RESEARCH',30,'SALES','ETC')
FROM EMP
ORDER BY DEPTNO;
if deptno = 10 then 'ACCOUNTING'
else if deptno =20 then 'RESEARCH'
else if deptno =30 then 'SALES'
else 'ETC'
CASE
- 조건절(if ~ else if ~ else) 연산자
- DECODE 연산자 기능 확장 & 성능 향상
- 비교/논리/SQL 연산자 사용 가능
SELECT [columns] CASE [column] WHEN value THEN target ... ELSE taget END ...- 단순 DECODE
SELECT DEPTNO,ENAME, -- Simple case
CASE DEPTNO WHEN '10' THEN 'ACCOUNTING' // 암시적(x), 에러 원인? 수정후 실행
WHEN 20 THEN 'RESEARCH'
WHEN 30 THEN 'SALES'
ELSE 'ETC'
END AS DEPARTMENT
FROM EMP
ORDER BY DEPTNO;
SELECT DEPTNO, ENAME,
DECODE(DEPTNO,10,'ACCOUNTING',20,'RESEARCH',30,'SALES','ETC')
FROM EMP
ORDER BY DEPTNO ;
- 범위 분류
SELECT DEPTNO, ENAME, SAL, -- Searched case
CASE WHEN SAL >= 4800 THEN 'HIGH' // 비교연산자
WHEN SAL BETWEEN 3000 AND 4799 THEN 'MID' // SQL 연산자
WHEN SAL >= 1000 AND SAL <=2999 THEN 'LOW' // 비교 & 논리 연산자
ELSE 'Passion pay'
END SAL_GRADE
FROM EMP
ORDER BY DEPTNO;
- NULL 처리
SELECT DEPTNO, ENAME, COMM,
CASE WHEN COMM >= 1000 THEN 'Great'
WHEN COMM >= 500 THEN 'Good'
WHEN COMM >= 0 THEN 'Bad'
ELSE 'Dreadful’ // ELSE에서 NULL Catch
END COMM_GRADE
FROM EMP
ORDER BY DEPTNO;
❏과제
- 부서별 차등 보너스를 계산하는 SQL 작성
- 10번 부서 급여의 0.3% , 20번부서 급여의 20%, 30번 부서 급여의 10%, 나머지 모든 부서 1%
- 부서 번호, 이름,직무,급여,보너스 출력
- 부서별, 최고 보너스 순서로 정렬
- 소수점 반올림
- 컬럼헤딩 변경시 컬럼 Alias 사용
SELECT DEPTNO, JOB, ENAME, SAL, NVL(comm,0) as comm_0, (SAL+ NVL(comm,0)) as totalsal,
CASE DEPTNO WHEN 10 THEN 0.003*(SAL+ NVL(comm,0))
WHEN 20 THEN 0.2*(SAL+ NVL(comm,0))
WHEN 30 THEN 0.1*(SAL+ NVL(comm,0))
ELSE 0.01*(SAL+ NVL(comm,0))
END BONUS
FROM EMP
ORDER BY DEPTNO, bonus desc;



C
Contents