














ROWNUM
- pseudocolumn : pseudo (실제 존재x, dynamic 생성, 읽기 전용)
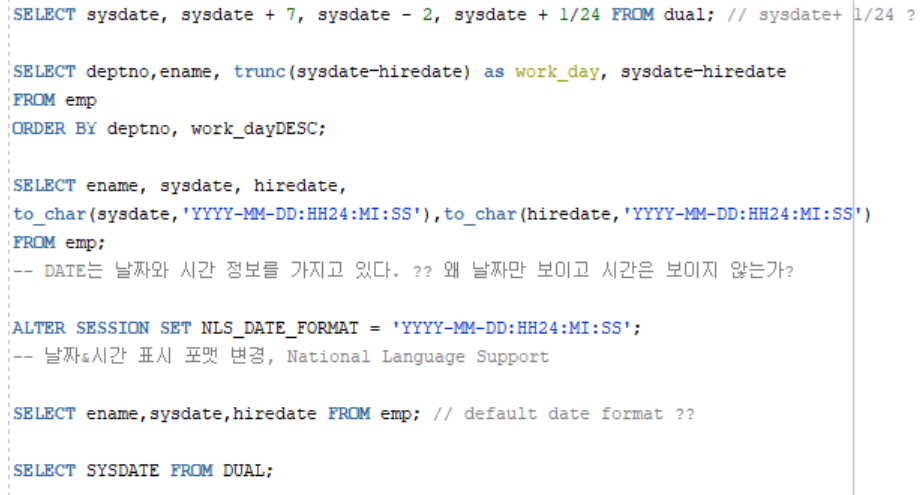
SELECT ROWNUM,ENAME,DEPTNO,SAL FROM EMP;
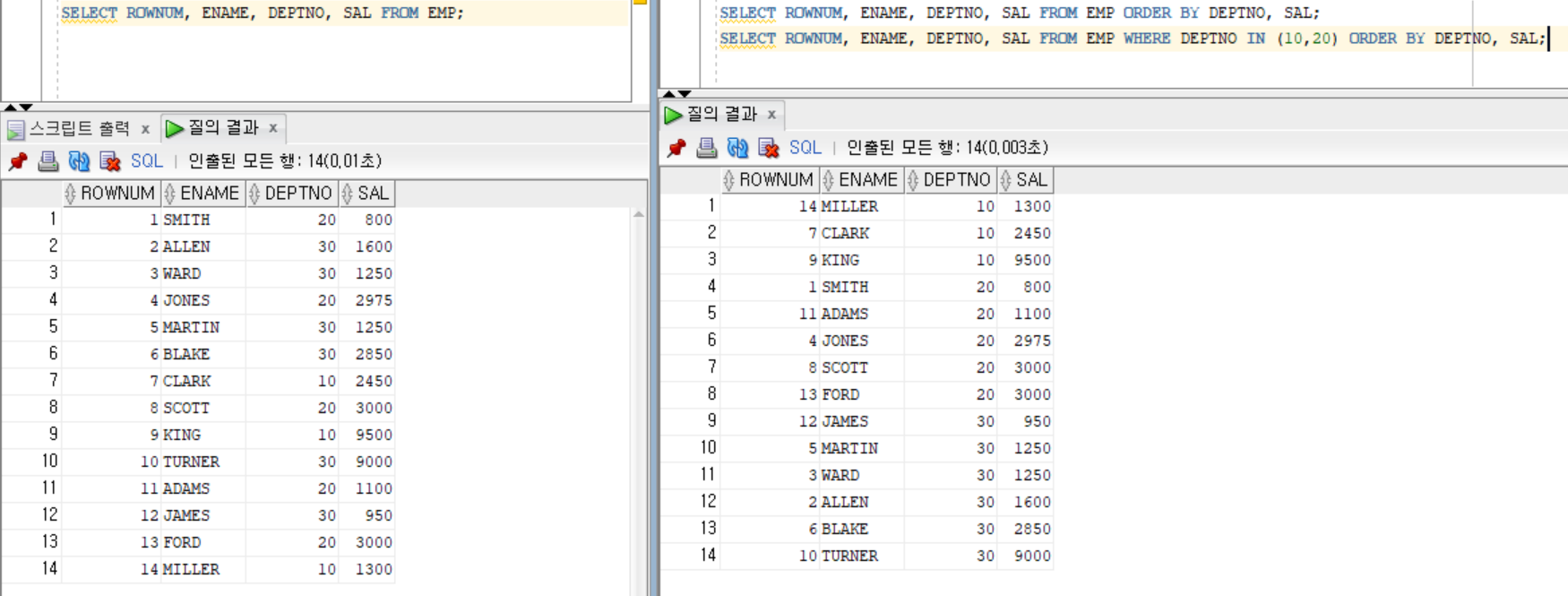
SELECT ROWNUM,ENAME,DEPTNO,SAL FROM EMP ORDER BY DEPTNO,SAL;
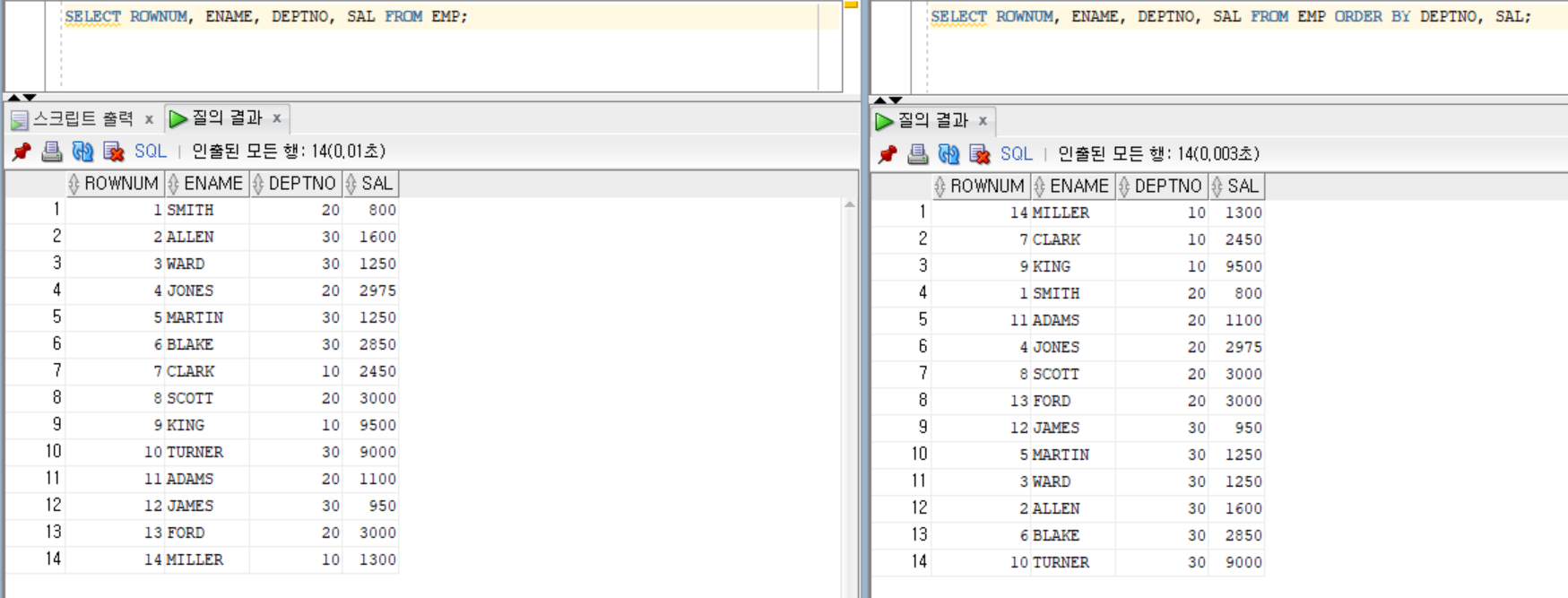
SELECT ROWNUM,ENAME,DEPTNO,SAL FROM EMP WHEREDEPTNO IN (10,20) ORDER BY DEPTNO,SAL;
-- 실행순서: WHERE>ROWNUM>ORDERBY
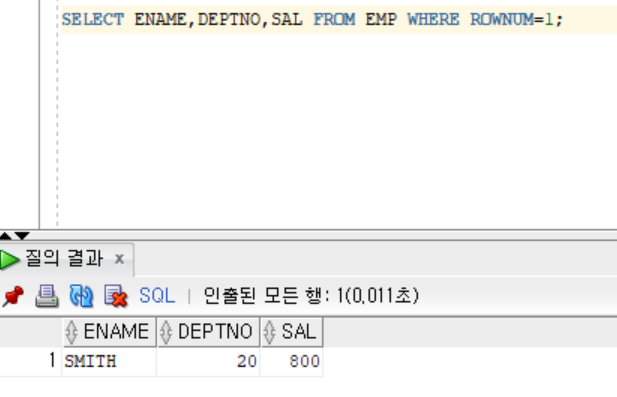
SELECT ENAME,DEPTNO,SAL FROM EMP WHERE ROWNUM=1; //O,1Row=1
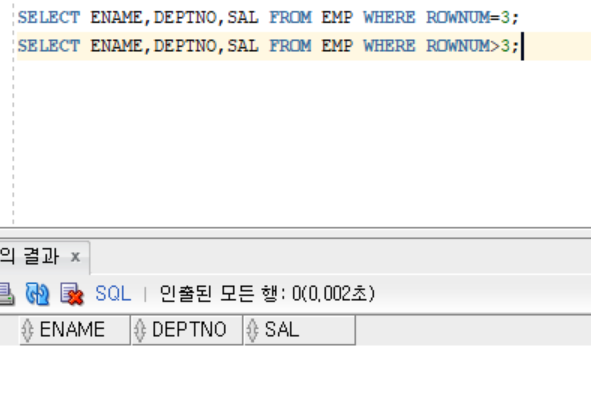
SELECT ENAME,DEPTNO,SAL FROM EMP WHERE ROWNUM = 3; // X
-- 1 Row != 3 ➔필터링➔2 Row가 1 Row가 되어 1 Row != 3 비교를 반복
SELECT ENAME,DEPTNO,SAL FROM EMP WHERE ROWNUM > 3; // X
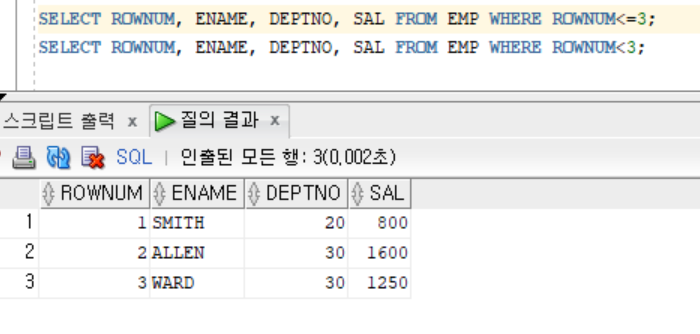
SELECT ENAME,DEPTNO,SAL FROM EMP WHERE ROWNUM <= 3; // O
SELECT ENAME,DEPTNO,SAL FROM EMP WHERE ROWNUM < 3; // O
함수
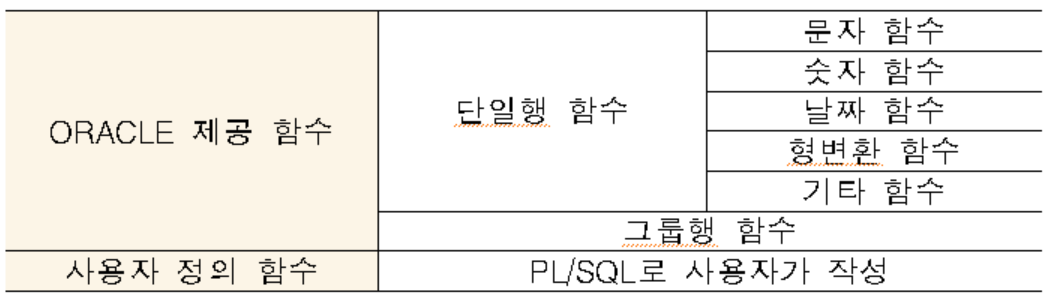
USER DEFINED FUNTION
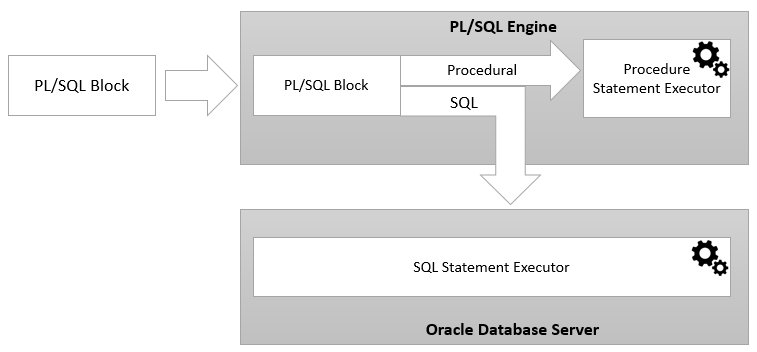
- PL/SQL (Procedural Language extension to SQL)
- SQL 확장
- PL/SQL 프로그램의 종류는 크게 Procedure, Function, Trigger 로 나뉘어 진다.
- 기존 비절차적 SQL에 절차(how) 정의
DECLARE
-- 변수 선언
BEGIN
-- 실행할 코드
EXCEPTION
-- 예외 처리 코드
END;
- 절차 정의, 모듈화(function, procedure) 가능
- 변수, 상수, 제어 구문 선언
- IF, CASE, LOOP 등
LOOP
-- 반복적으로 실행할 코드
EXIT WHEN 조건; -- 반복문을 종료할 조건
END LOOP;
- 예외처리
BEGIN
-- 예외가 발생할 수 있는 코드
EXCEPTION
WHEN 예외1 THEN
-- 예외1에 대한 처리 코드
WHEN 예외2 THEN
-- 예외2에 대한 처리 코드
...
WHEN OTHERS THEN
-- 다른 예외에 대한 처리 코드
END;
ORACLE DEFINED FUNTION
입력을 기준으로 single, group으로 나뉨
출력은 항상 단일(1개)
single : N → N
group : N → 0+
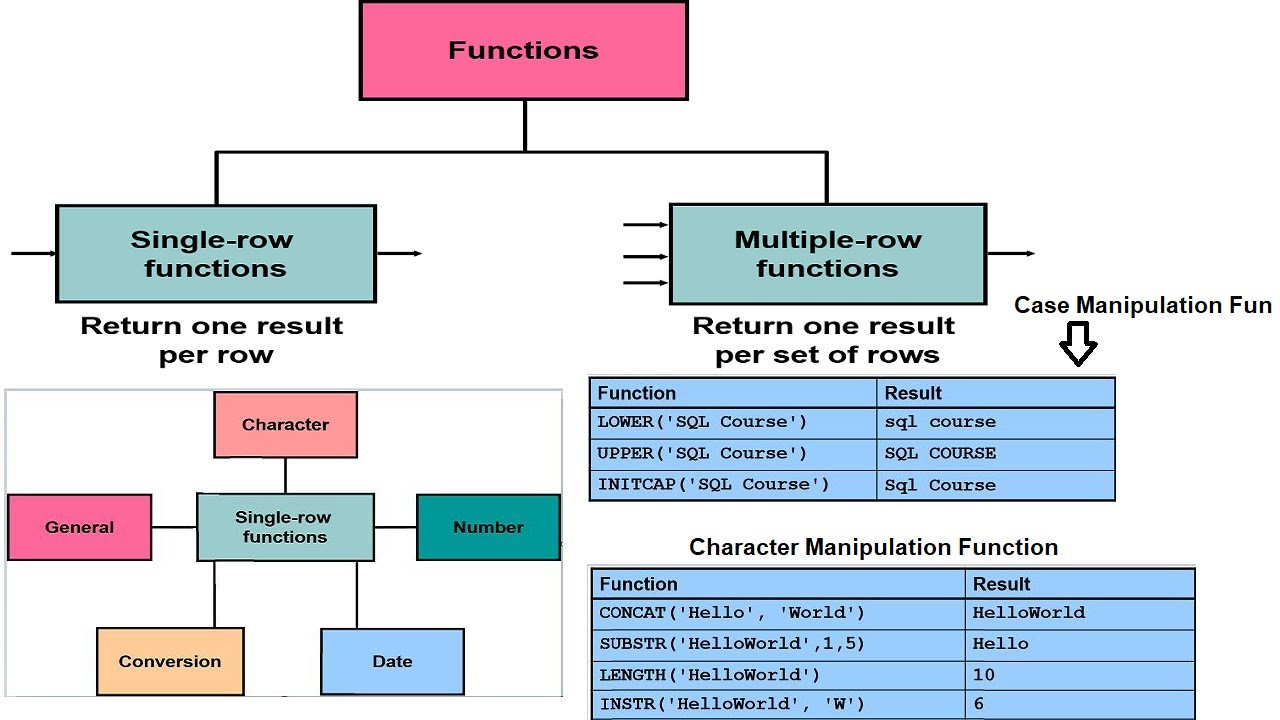
- SINGLE ROW FUNCTION (단일행 함수) : 1개의row에 적용되고1 row당1개의 결과return
- input (N) → output (N)
- 사용되는 위치: select list , where, order by, group by
- 함수 종류
-
- 문자함수
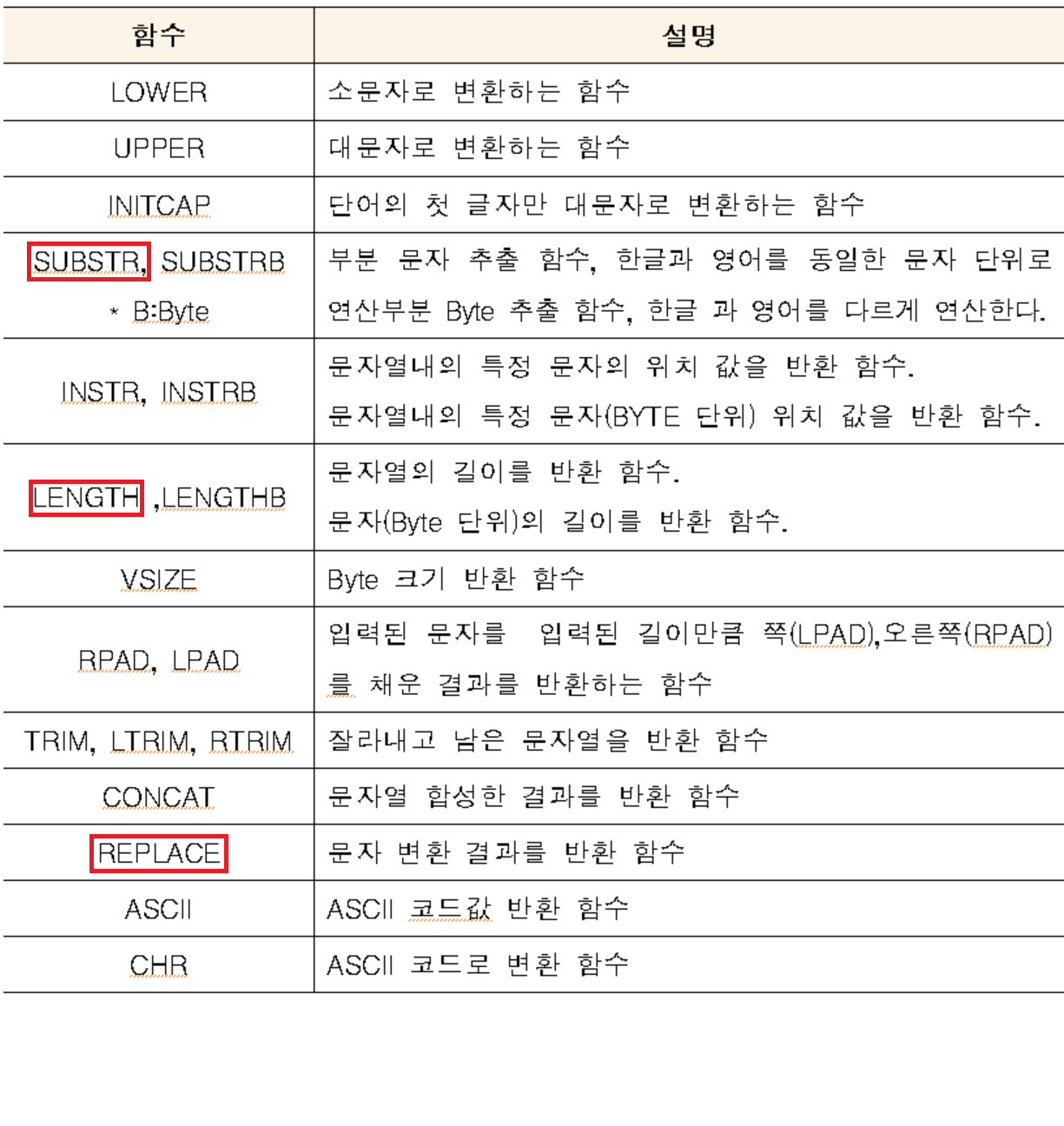
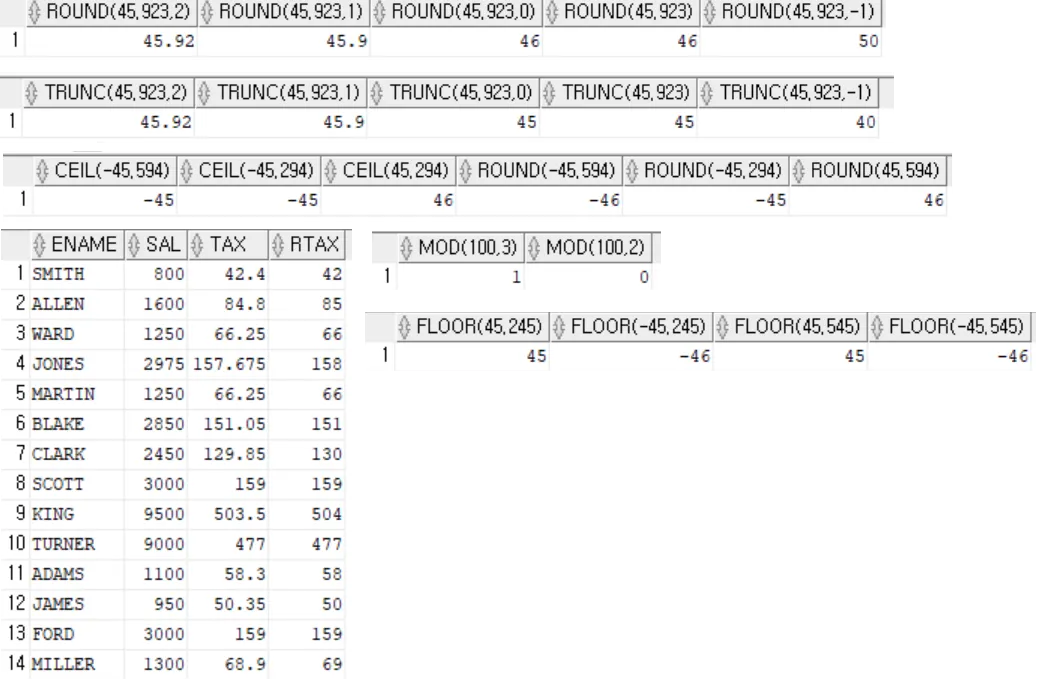
- 숫자함수
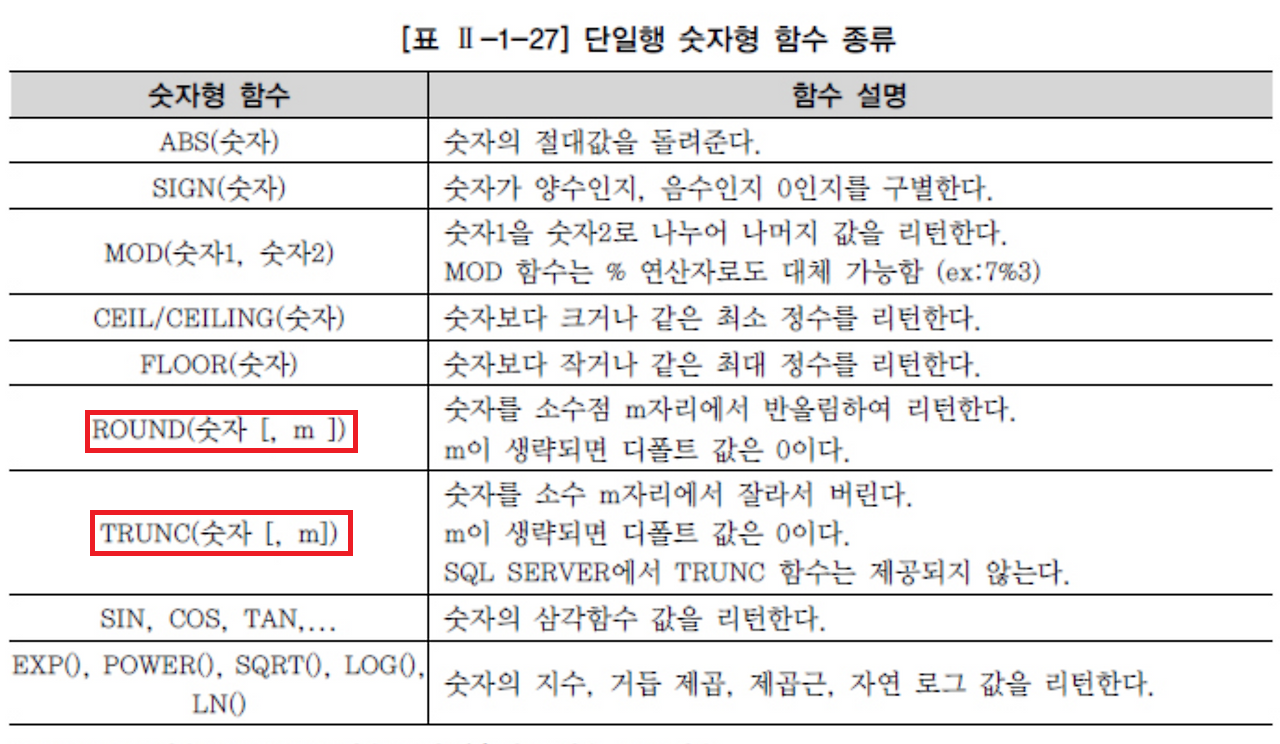
- 날짜함수
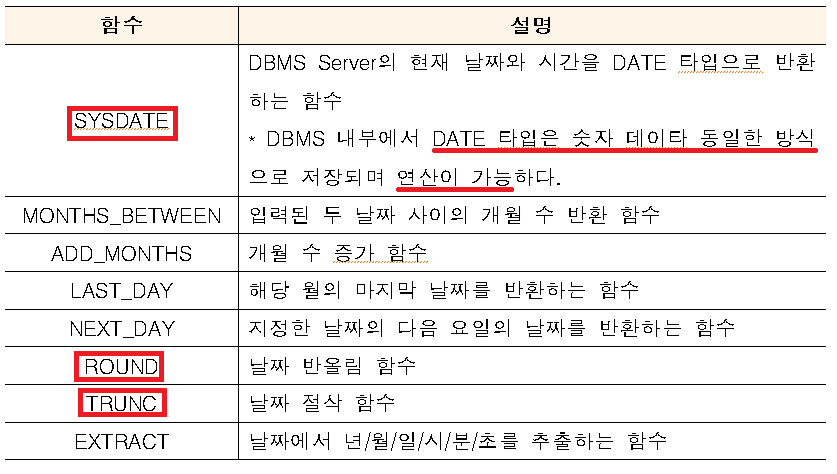
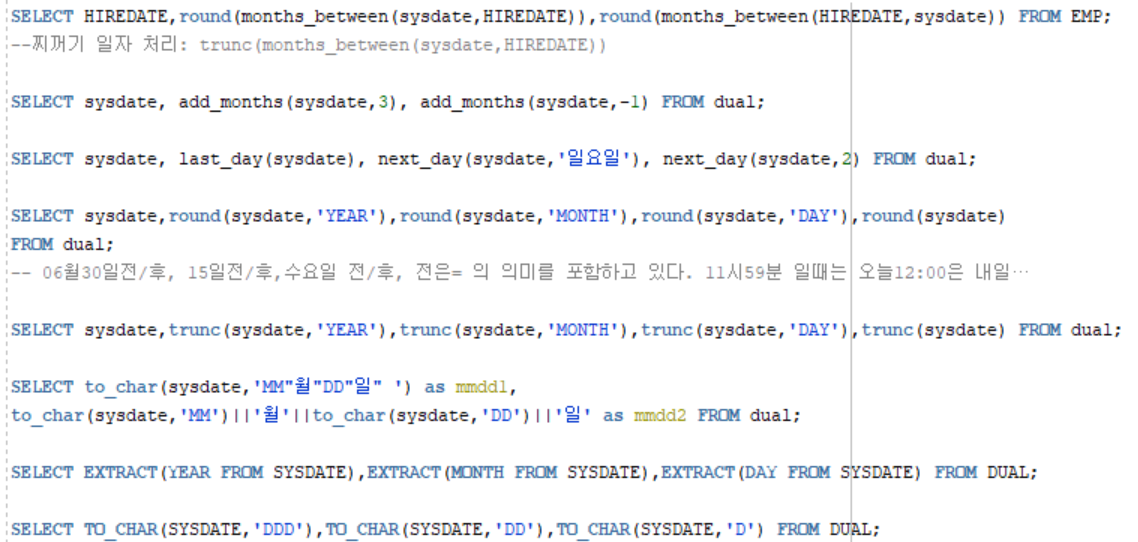
함수 내용 DATE_FORMAT (날짜, ‘FORMAT’) 날짜를 해당 포멧으로 변환 DATE (날짜) 날짜를 ‘연도-월-일’로 변환 YEAR (날짜) 날짜의 연도 반환 MONTH (날짜) 날짜의 월 반환 - 변환함수(DATA TYPE CONVERSION)
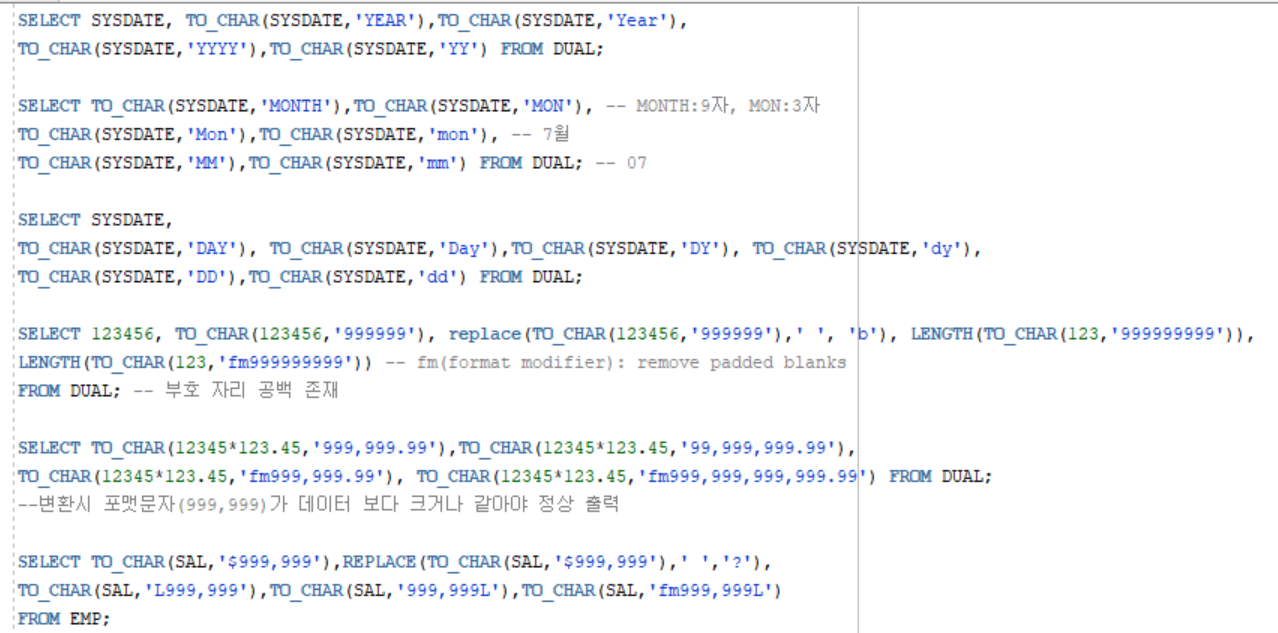
함수 명 기능 사용 예 TO_NUMBER( char ) char을 숫자로 변환 SELECT TO_NUMBER ( ‘12345’ ) FROM DUAL; → 12345 TO_CHAR( n, number_format ) 숫자인 n을 number_format에 맞게 문자로 변환, number_format은 생략 가능 SELECT TO_CHAR ( 12345, ‘99,999’ ) FROM DUAL; → ‘12,345’ TO_CHAR( date, date_format ) 날짜인 date를 date_format에 맞게 문자로 변환, date_format은 생략 가능 SELECT TO_CHAR ( SYSDATE, ‘YYYY-MM-DD HH 24:MI: SS’ ) FROM DUAL; → ‘2019-04-08 23:52:01’ TO_DATE( char, date_format ) 문자 char을 date_format에 맞게 날짜로 변환, date_format은 생략 가능 SELECT TO_DATE ( ‘2019-04-08 23:52:01’, ‘YYYY-MM-DD HH 24:MI: SS’ ) FROM DUAL; → 2019-04-08 23:52:01
- GROUP ROW FUNCTION (그룹행 함수) : input (N) → output (1)
- AVG, SUM, COUNT
- COUNT (*) : record의 개수를 셈, 해당 결과를 기준으로 count 실행
- NULL 제외한 나머지 data 처리
GROUP BY [columns]: column들을 기준으로 data 처리
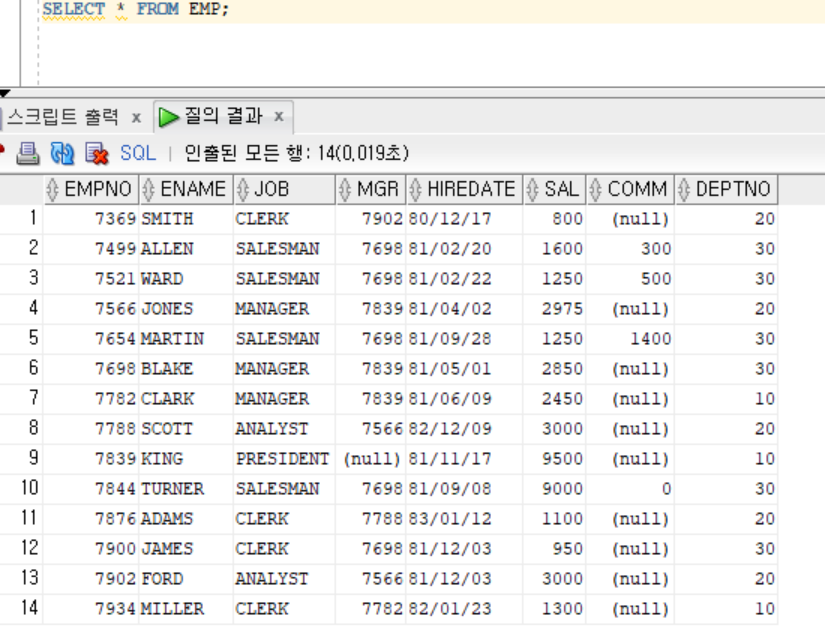
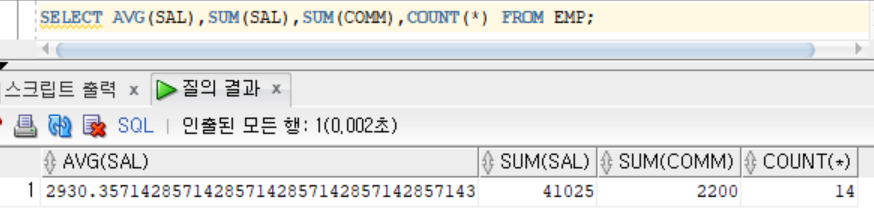
SELECT AVG(SAL),SUM(SAL),SUM(COMM),COUNT(*) FROM EMP; // 14건 입력, 1건 출력
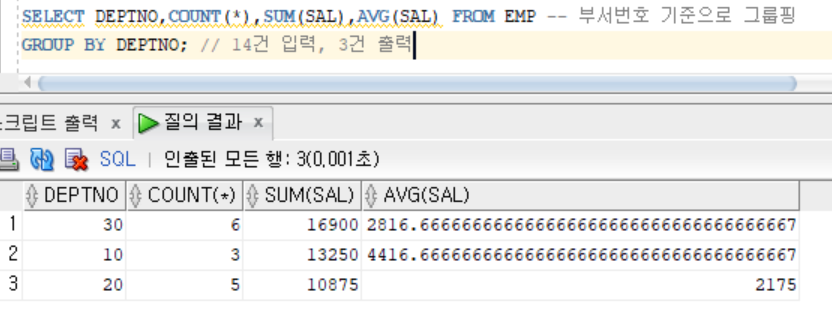
SELECT DEPTNO,COUNT(*),SUM(SAL),AVG(SAL) FROM EMP // 부서번호 기준으로 그룹핑
GROUP BY DEPTNO; // 14건 입력, 3건 출력
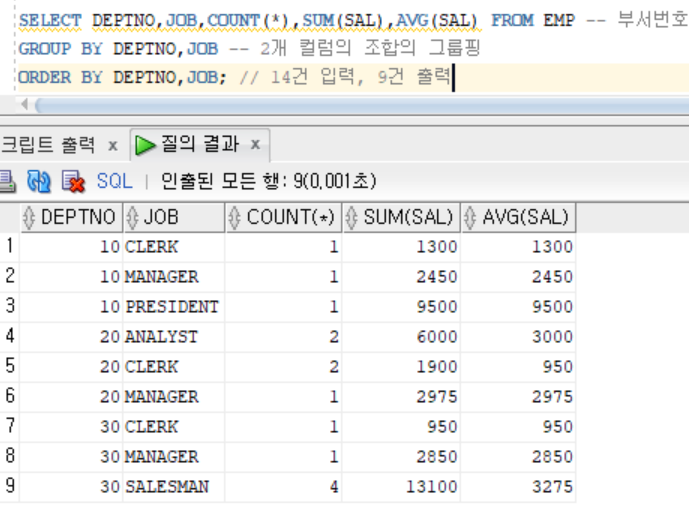
SELECT DEPTNO,JOB,COUNT(*),SUM(SAL),AVG(SAL) FROM EMP // 부서번호,직무 기준으로 그룹핑
GROUP BY DEPTNO,JOB // 2개 컬럼의 조합의 그룹핑
ORDER BY DEPTNO,JOB; // 14건 입력, 9건 출력
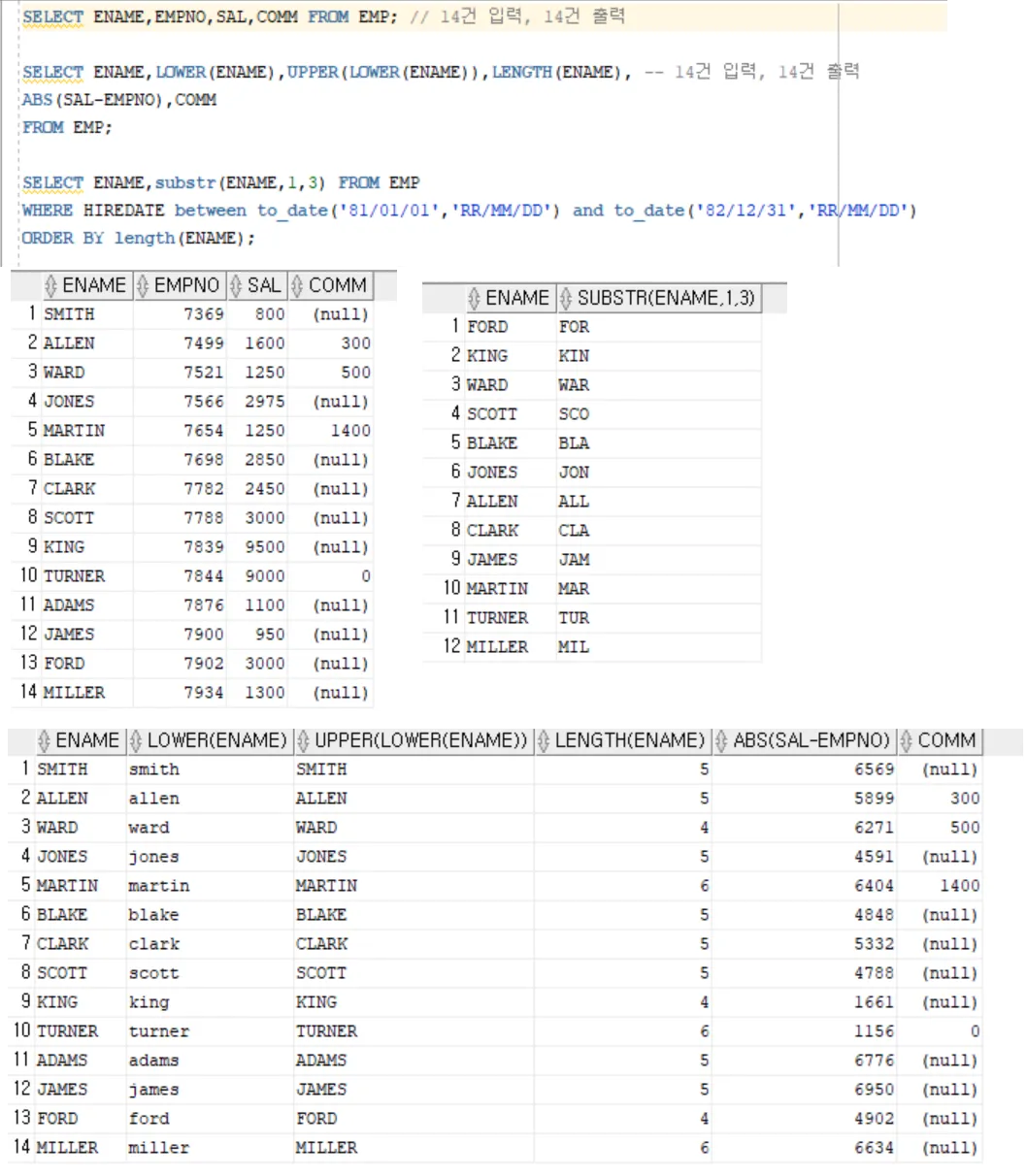
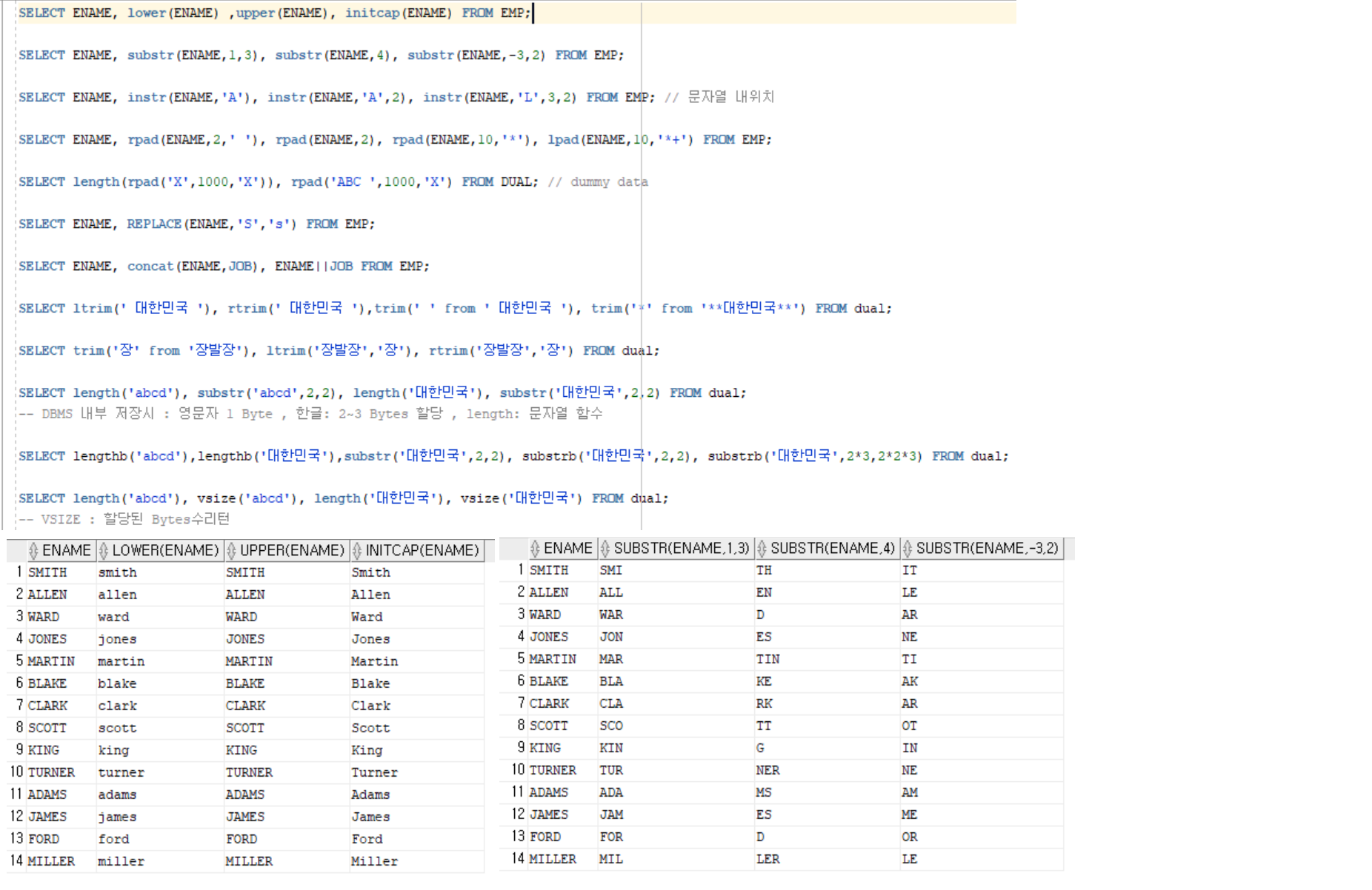
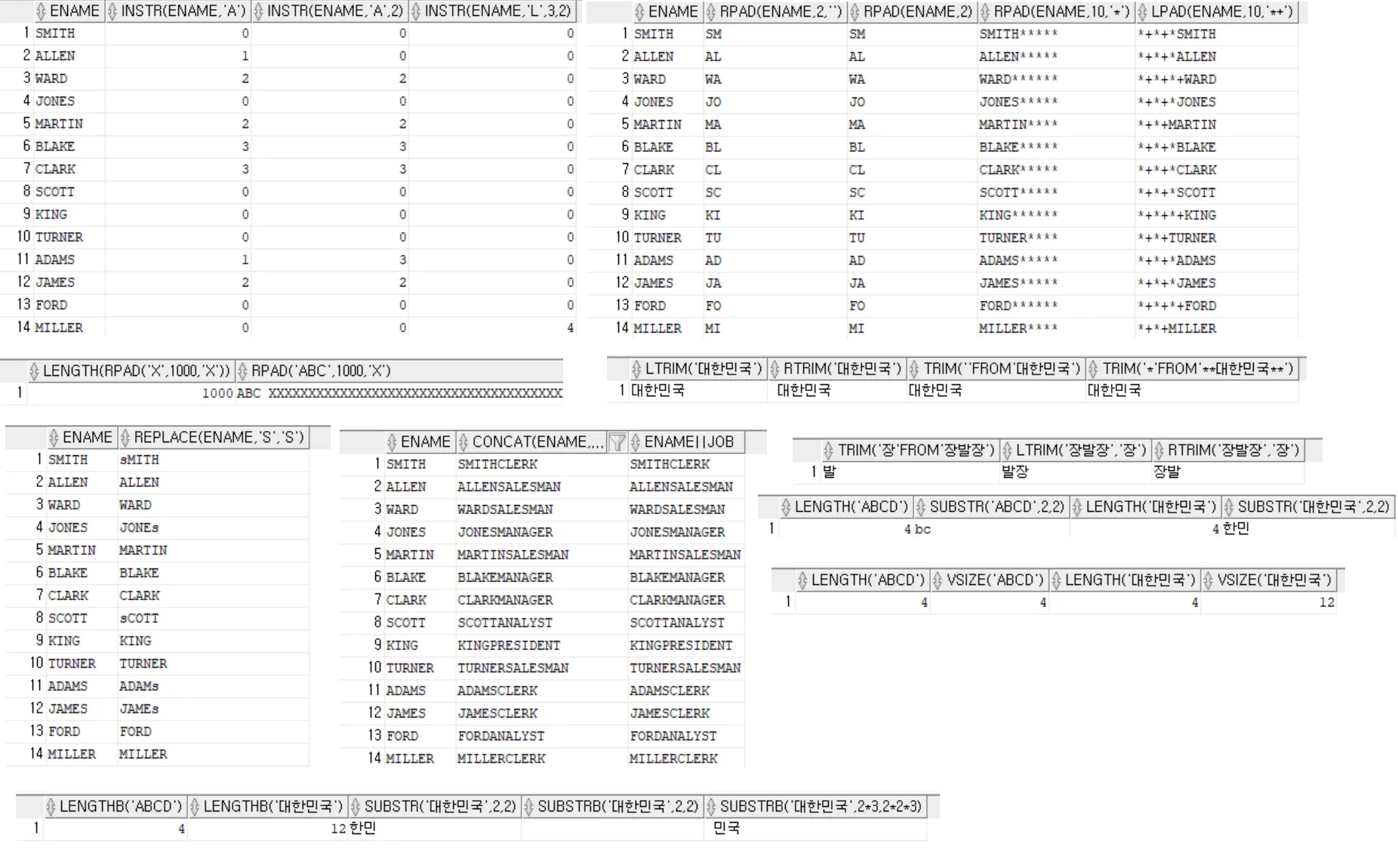
문자열 함수
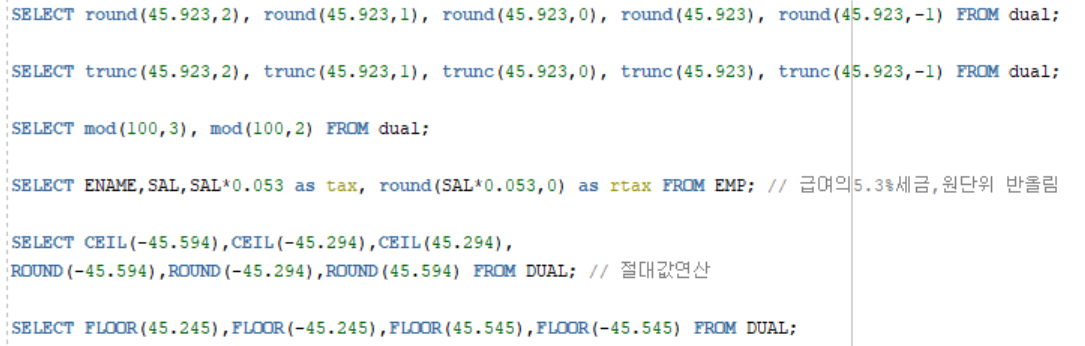
숫자 함수
날짜 함수
- ※
SELECT sid FROM v$mystat: 동일 session worksheet → 동일 SID
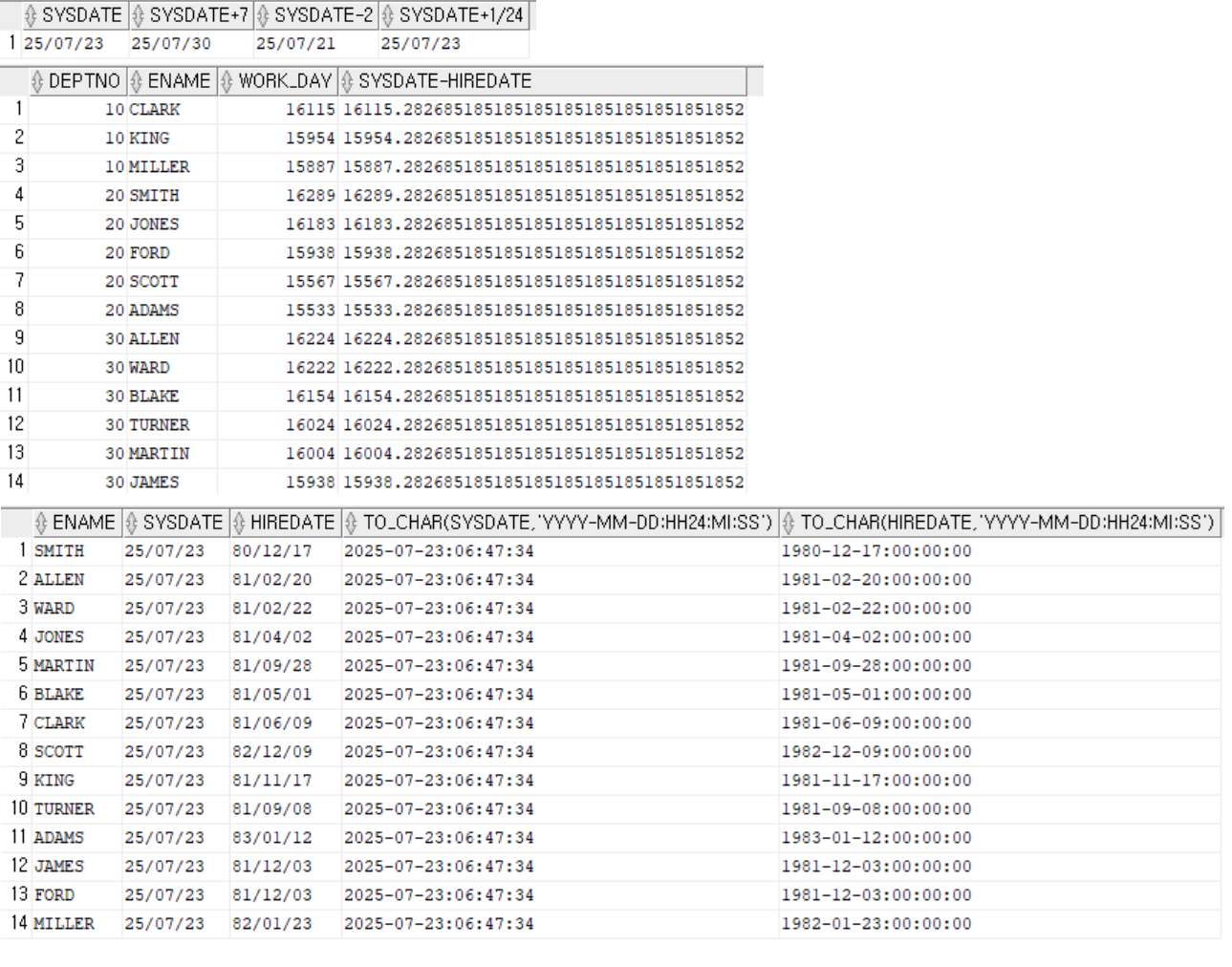
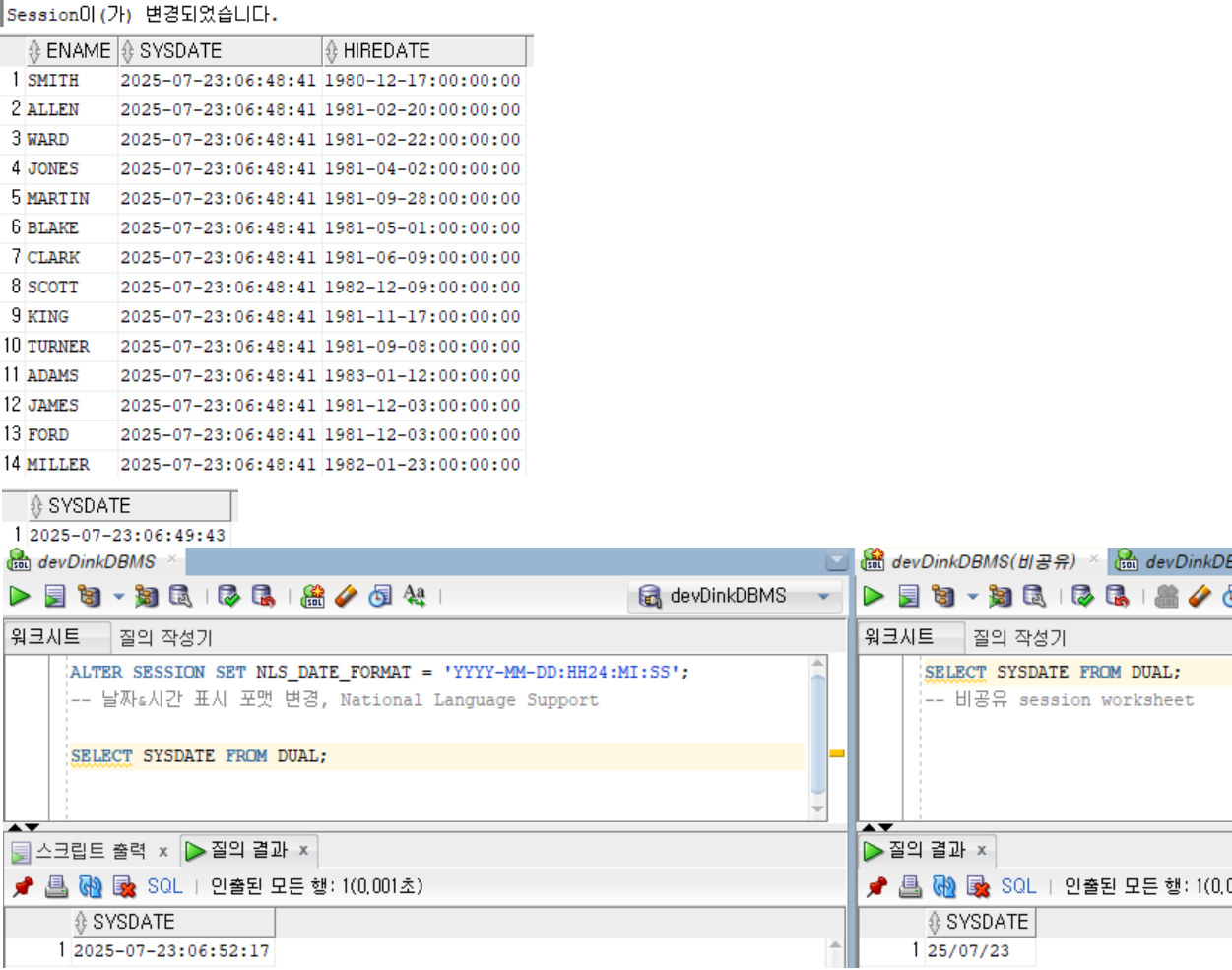
to_char(num): 부호 자리 존재format: case-insensitive(단 ‘YEAR’, ‘Year’ 예외)
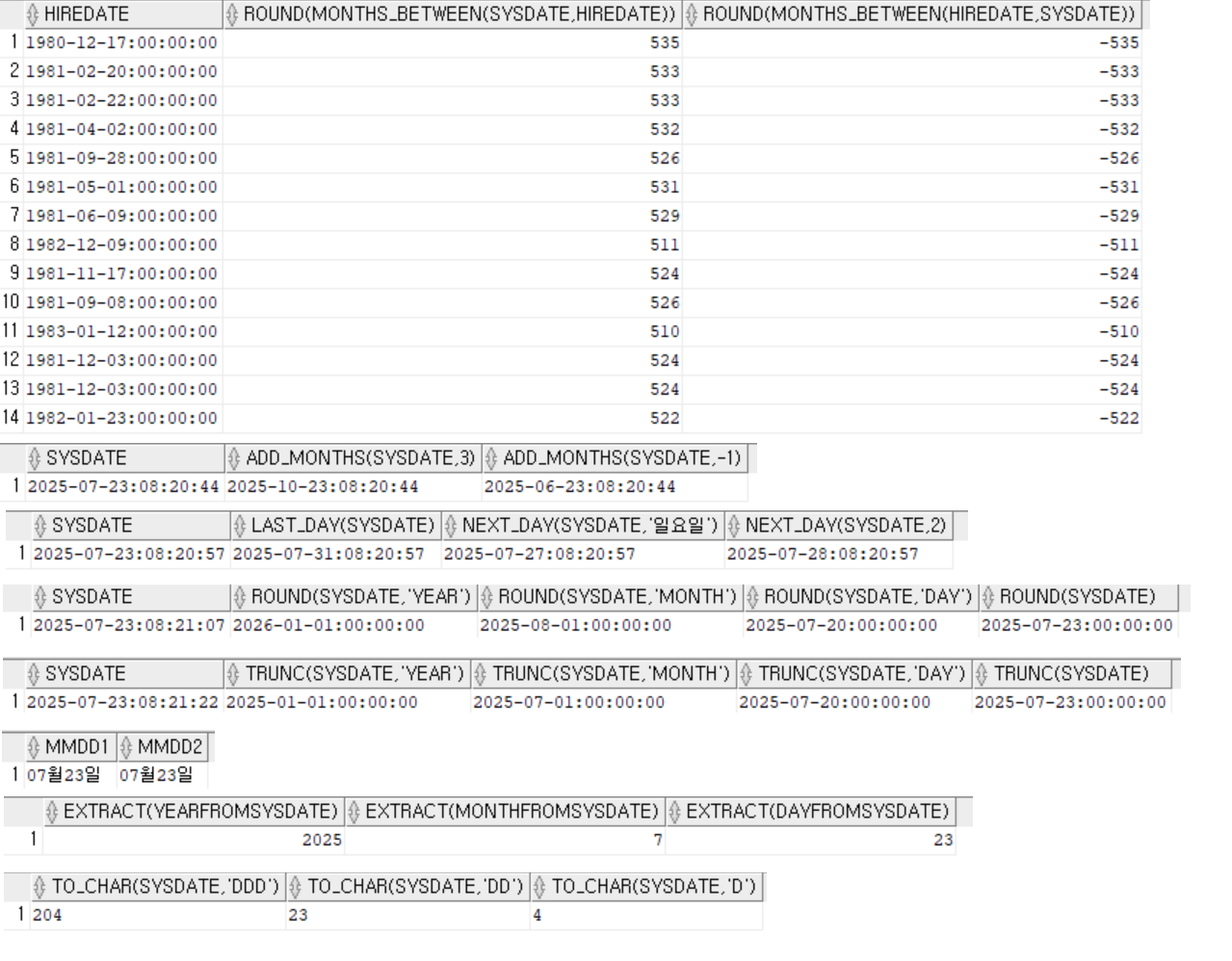
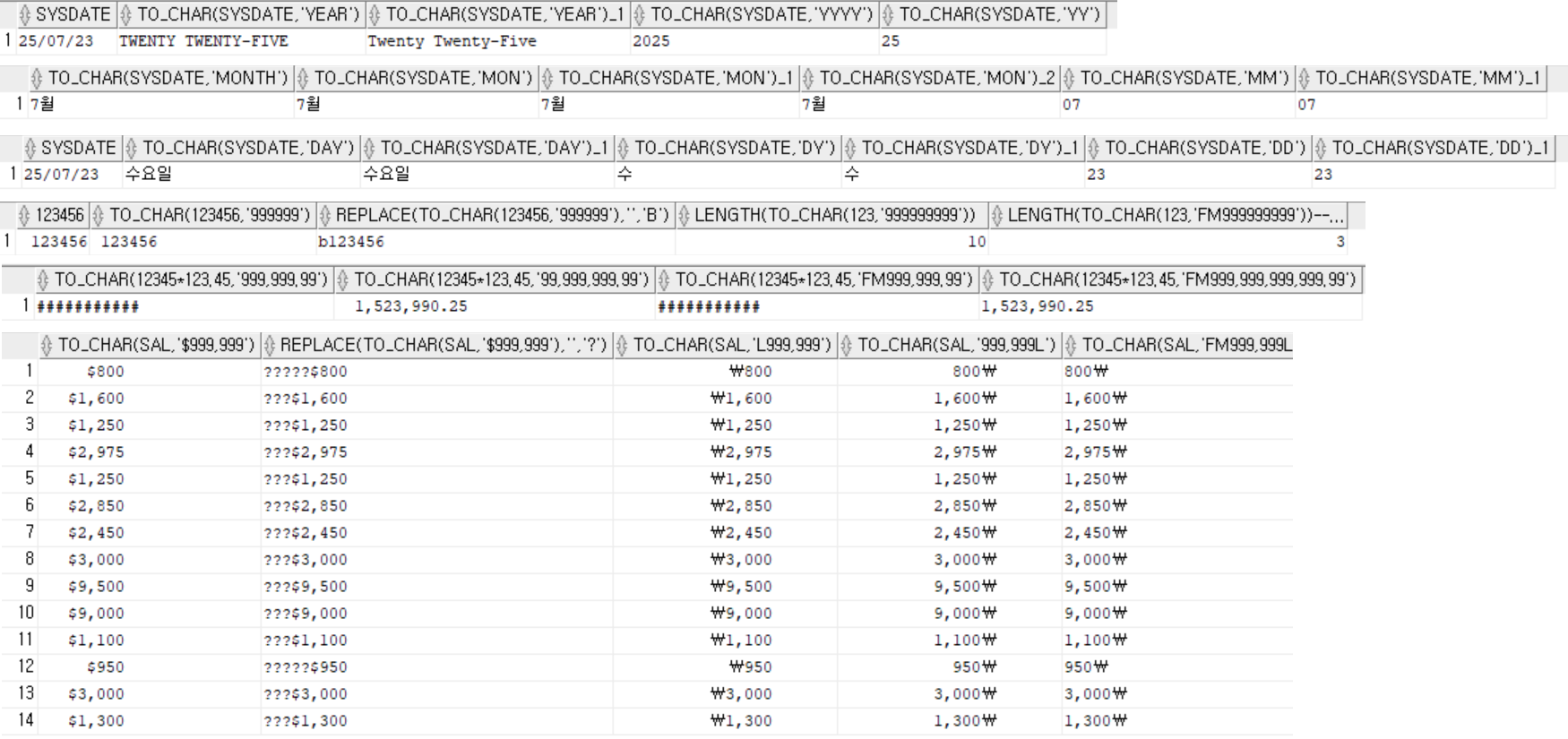
- 그룹행 함수
COUNT(*): FROM -(record) 의 개수COUNT([column]): coulumn (data)의 개수, NOT NULL일 경우 column의 개수 == recordAVG(COMM)==SUM(COMM)/COUNT(COMM)≠SUM(COMM)/COUNT(*)
GROUP BY, HAVING
GROUP BY: 기준 column 동일한 데이터 gropingHAVING: gouping된 data를 기준으로 WHERE 실행
| 공통점 | 차이점(기준) | |
|---|---|---|
| WHERE | 조건절 | TABLE |
| HAVING | 조건절 | GROUP |
SELECT MIN(ENAME),MAX(ENAME),MIN(SAL),MAX(SAL),MIN(HIREDATE),MAX(HIREDATE) FROM EMP;
-- ENAME:문자, SAL:숫자, HIREDATE:날짜
SELECT COUNT(*), COUNT(EMPNO), COUNT(MGR), COUNT(DISTINCT MGR), COUNT(COMM) FROM EMP;
-- 그룹행 함수에서는 NULL을 무시하고 연산 수행
SELECT COUNT(JOB),COUNT(ALL JOB),COUNT(DISTINCT JOB),SUM(SAL),SUM(DISTINCT SAL) FROM EMP;
-- DISTINCT 연산 수행후 COUNT 수행
SELECT COUNT(*), SUM(COMM), SUM(COMM)/COUNT(*),AVG(COMM),SUM(COMM)/COUNT(COMM) FROM EMP;
-- SUM(COMM)/COUNT(*) 와 AVG 결과가 다른 이유?
SELECT SAL,COMM FROM EMP;
-- 그룹행 함수 와NULL 그리고NVL , 효율적인 계산방안은?
SELECT
SUM(NVL(COMM,0)) AS SUM_COMM1,
SUM(COMM) AS SUM_COMM2,
NVL(SUM(COMM),0) AS SUM_COMM3
FROM EMP;
MIN(ENAME) MAX(ENAME) MIN(SAL) MAX(SAL) MIN(HIRE MAX(HIRE
---------- ---------- ---------- ---------- -------- --------
ADAMS WARD 800 9500 80/12/17 83/01/12
COUNT(*) COUNT(EMPNO) COUNT(MGR) COUNT(DISTINCTMGR) COUNT(COMM)
---------- ------------ ---------- ------------------ -----------
14 14 13 6 14
COUNT(JOB) COUNT(ALLJOB) COUNT(DISTINCTJOB) SUM(SAL) SUM(DISTINCTSAL)
---------- ------------- ------------------ ---------- ----------------
14 14 5 41025 36775
COUNT(*) SUM(COMM) SUM(COMM)/COUNT(*) AVG(COMM) SUM(COMM)/COUNT(COMM)
---------- ---------- ------------------ ---------- ---------------------
14 5225 373.214286 373.214286 373.214286
SAL COMM
---------- ----------
800 275
1600 300
1250 500
2975 275
1250 1400
2850 275
2450 275
3000 275
9500 275
9000 275
1100 275
SAL COMM
---------- ----------
950 275
3000 275
1300 275
14개 행이 선택되었습니다.
SUM_COMM1 SUM_COMM2 SUM_COMM3
---------- ---------- ----------
5225 5225 5225

SELECT DEPTNO,COUNT(*) FROM SCOTT.EMP GROUP BY DEPTNO;
SELECT DEPTNO,ROUND(AVG(SAL), 2) ,SUM(SAL) FROM EMP GROUP BY DEPTNO;
SELECT DEPTNO,ROUND(AVG(SAL), 2) ,SUM(SAL) FROM EMP
GROUP BY DEPTNO
ORDER BY DEPTNO;
SELECT DEPTNO,ROUND(AVG(SAL),1) ,SUM(SAL) FROM EMP
GROUP BY DEPTNO
ORDER BY DEPTNO;
SELECT COMM,COUNT(*) FROM EMP GROUP BY COMM;// NULL 그룹핑 대상인가 ? - Y
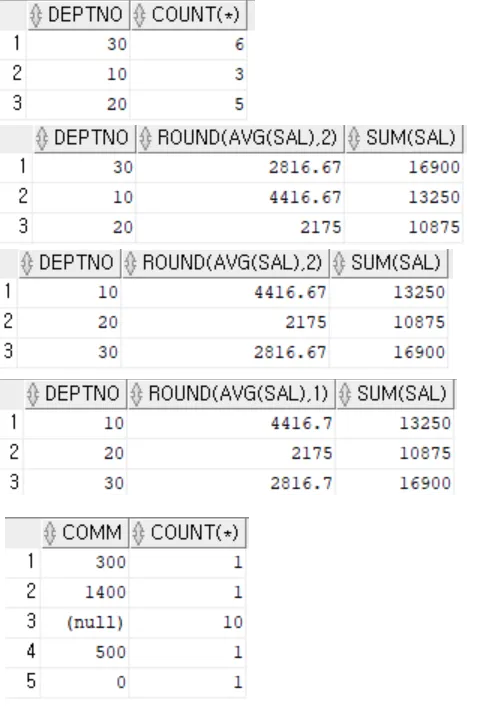
SELECT DEPTNO,COUNT(*),SUM(SAL),ROUND(AVG(SAL),1) FROM EMP
GROUP BY DEPTNO;
SELECT DEPTNO,COUNT(*),SUM(SAL),ROUND(AVG(SAL),1) FROM EMP
GROUP BY DEPTNO
HAVING SUM(SAL) >= 9000;
SELECT DEPTNO,COUNT(*),SUM(SAL),ROUND(AVG(SAL),1) FROM EMP
GROUP BY DEPTNO
HAVING SUM(SAL) >= 11000;
SELECT DEPTNO,COUNT(*),SUM(SAL),ROUND(AVG(SAL),1) FROM EMP
GROUP BY DEPTNO
HAVING DEPTNO in (10,20);
SELECT DEPTNO,ROUND(AVG(SAL),1) ,SUM(SAL) FROM EMP
WHERE DEPTNO IN (10,20)
GROUP BY DEPTNO
HAVING SUM(SAL) >= 9000
ORDER BY DEPTNO DESC;
-- GROUP 실행순서 : FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY
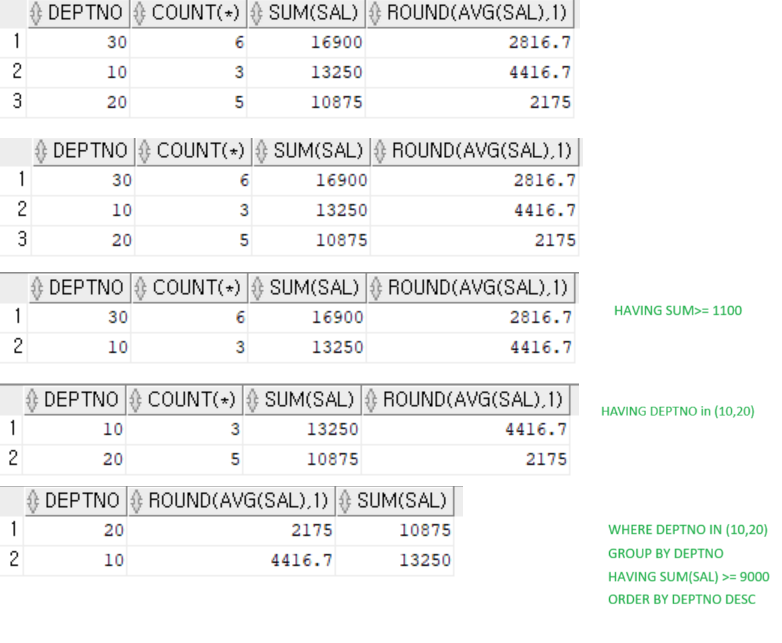
SELECT DEPTNO, MIN(SAL), MAX(SAL) FROM EMP GROUP BY DEPTNO ORDER BY DEPTNO;
SELECT to_char(hiredate, 'YYYY') AS HIREYEAR, MIN(SAL), MAX(SAL)
FROM EMP GROUP BY to_char(hiredate, 'YYYY');
SELECT SUM(CASE WHEN DEPTNO = 10 THEN 1 ELSE 0 END) AS "10번부서",
SUM(CASE WHEN DEPTNO = 20 THEN 1 ELSE 0 END) AS "20번부서",
SUM(CASE WHEN DEPTNO = 30 THEN 1 ELSE 0 END) AS "30번부서"
FROM EMP;
SELECT
SUM(DECODE(DEPTNO, 10, 1, 0)) AS "10번부서",
SUM(DECODE(DEPTNO, 20, 1, 0)) AS "20번부서",
SUM(DECODE(DEPTNO, 30, 1, 0)) AS "30번부서"
FROM EMP;
SELECT
DECODE(DEPTNO, 10, 1, 0) AS "10번부서",
DECODE(DEPTNO, 20, 1, 0) AS "20번부서",
DECODE(DEPTNO, 30, 1, 0) AS "30번부서"
FROM EMP;
10번부서 20번부서 30번부서
------------------------------
3 5 6



C
Contents