














SubQuery
Main Query(SELECT,INSERT,DELETE,UPDATE,CREATE)안에 포함되는 SELECT
- Main Query : DML + CREATE
- Sub Query : SELECT
- 실행 : Sub → Main
- (예외) Correlated Subquery (상관서브쿼리) : Main, Sub 상관관계
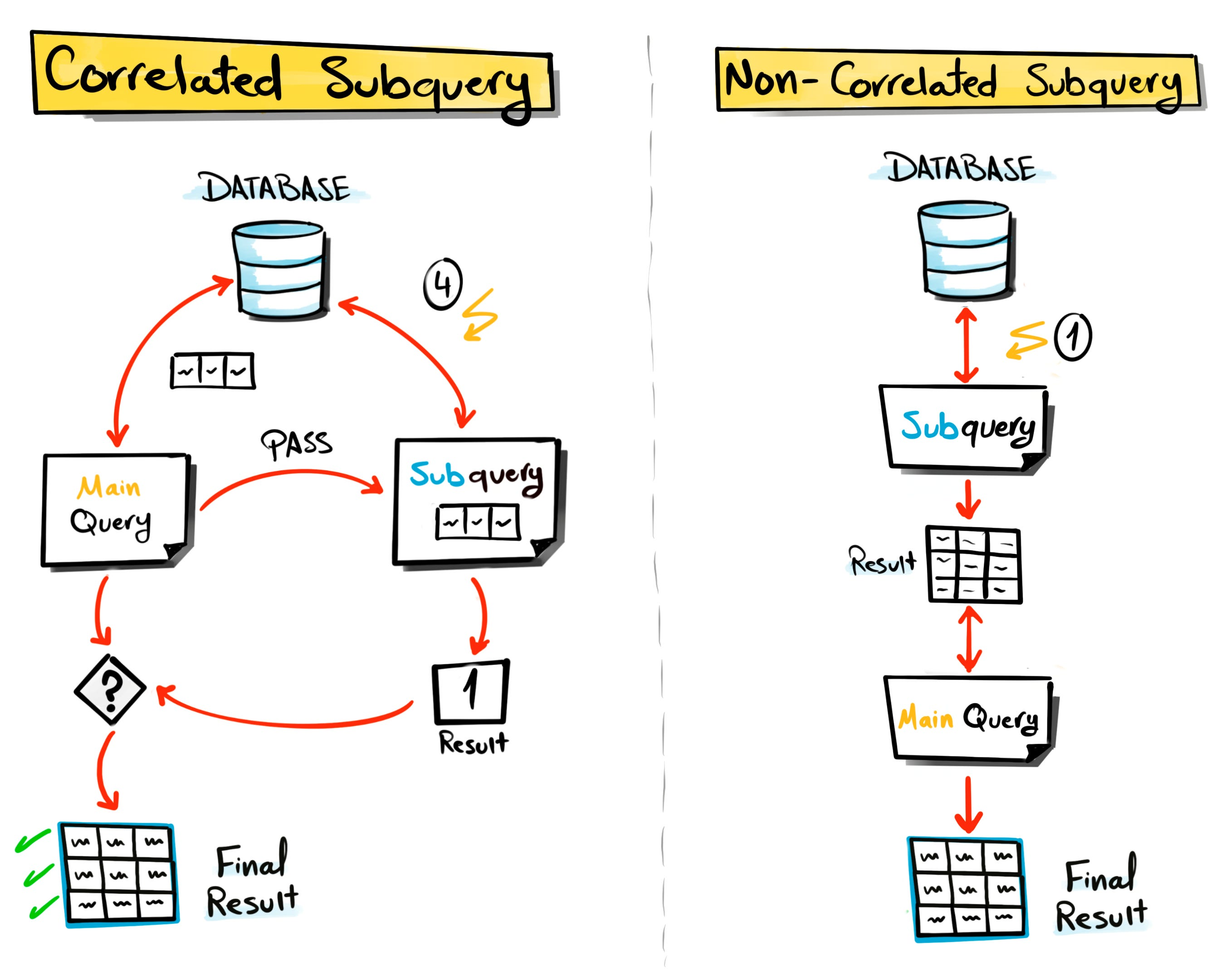
- 실행 횟수↓
- request 실행 횟수 감소 → 전송 및 데이터 송/수신 감소
- Sub에서 이미 실행한 조건문은 다시 실행할 필요 X → 조건문 수행 횟수 감소

※ 종류
| Scalar Subquery | |
|---|---|
| (↔composit) | Select List에서 컬럼대신 사용, 단일값(1행, 1열 값)을 리턴하고 컬럼대신 사용 |
| Inline View | FROM절에 테이블 대신 사용 |
| Nested Subquery | WHERE ,HAVING절에 사용되는SubQuery |
분류
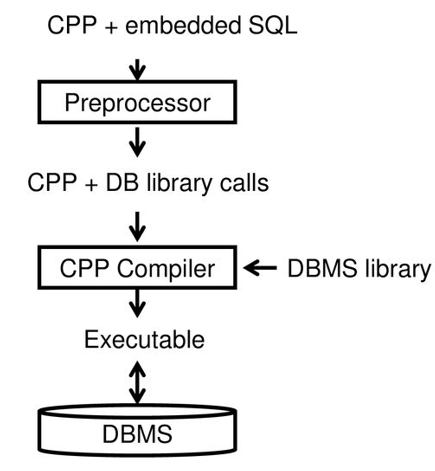
- Interactive SQL
- SQL Query를 SQL 내에서 처리/확인 후 process(HOST)에 적용
- Embedded SQL
- languge(HOST)에 포함된 SQL 구문
Return 값에 의한 분류
SINGLE COLUMN, SINGLE ROW
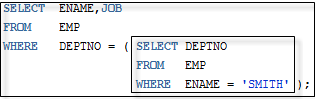
SELECT ENAME,JOB FROM EMP
WHERE DEPTNO = (SELECT DEPTNO FROM EMP WHERE ENAME = 'SMITH' );
SELECT ENAME,SAL FROM EMP WHERE SAL < ( SELECT AVG(SAL) FROM EMP);
SINGLE COLUMN, MULTIPLE ROW RETURN SUBQUERY
SELECT ENAME,JOB FROM EMP WHERE DEPTNO = 10,30; // error, single=single
SELECT ENAME,JOB FROM EMP WHERE DEPTNO IN (10,30);
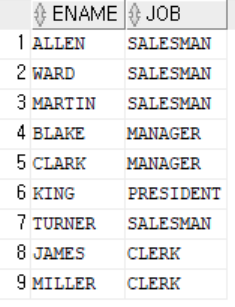
-- 3인 이상 근무부서정보조회
SELECT DNAME,LOC FROM DEPT
WHERE DEPTNO =(SELECT DEPTNO FROM EMP GROUP BY DEPTNO HAVING COUNT(*) > 3 ); // error
SELECT DNAME,LOC FROM DEPT
WHERE DEPTNO IN (SELECT DEPTNO FROM EMP GROUP BY DEPTNO HAVING COUNT(*) > 3);
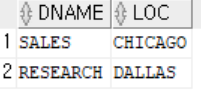
MULTIPLE COLUMN, MULTIPLE ROW RETURN
SELECT DEPTNO,JOB,ENAME,SAL FROM EMP
WHERE (DEPTNO,JOB) IN
(SELECT DEPTNO,JOB FROM EMP GROUP BY DEPTNO,JOB HAVING AVG(SAL) > 2000);
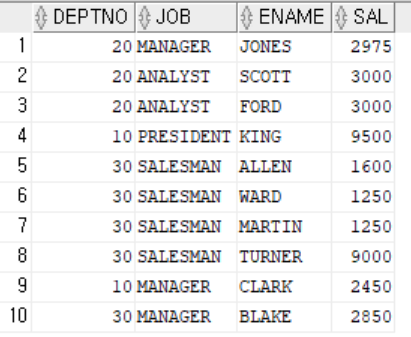
동작하는 방식에 따른 분류
- Normal Subquery
- 서브쿼리가 메인쿼리의 컬럼을 참조하지 않는다.
- 메인쿼리에 값(서브쿼리의 실행결과)을 제공하는 목적으로 사용
- Correlated Subquery
- 서브쿼리가 메인쿼리의 컬럼을 참조 한다.
- 메인 쿼리가 먼저 실행되고 서브쿼리에서 필터링 하는 목적으로 사용
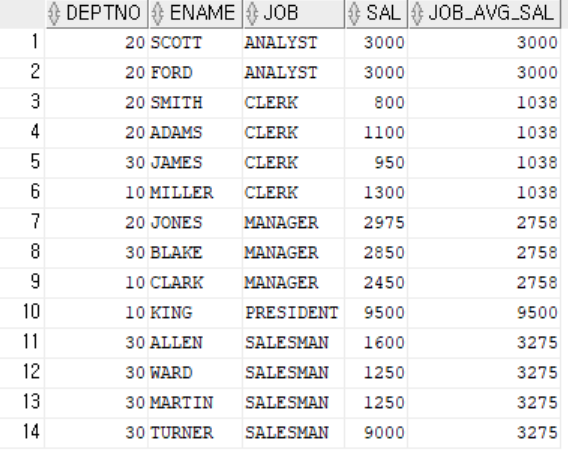
Scalar Subquery
- 장점 : 편리성
- 그룹행 함수 - 연산 부담↑
- 입/출력값, Query Execution Cache, hashing
- Query Execution Cache
- H/W cache
- S/W cache : 자주 사용하는 data 혹은 이미 실행한 data(Query)를 기억해둠
- ANALYST를 계산
→ 계산 결과를 TABLE 등으로 임시 저장
→ 다음 동일한 JOB data 발생 시 cache값 참고
// 직무별 평균 연봉
SELECT
DEPTNO,
ENAME,
JOB,
SAL,
(SELECT ROUND(AVG(SAL),0) FROM EMP S WHERE S.JOB=M.JOB) AS JOB_AVG_SAL
FROM EMP M
ORDER BY JOB; // 실행계획(?) outer-join ➔결과가 없으면 NULL 리턴
CORRELATED SUBQUERY(상관서브쿼리)
- Subquery는Mainquery의 컬럼을 참조할 수 있지만Mainquery는Subquery의 컬럼을참조할수 없다
- Mainquery에서Subquery의 컬럼을 참조 하려면 →①Join 으로 변환 ②Scalar Subquery
SELECT DEPTNO,ENAME,JOB,SAL FROM EMP M
WHERE SAL > ( SELECT AVG(SAL) AS AVG_SAL FROM EMP WHERE JOB = M.JOB );
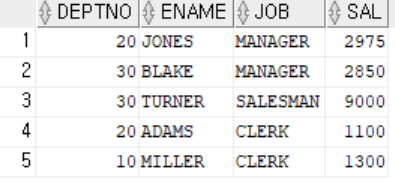
In-Line View (FROM 절에 사용된 SUBQUERY)
- SELECT의 결과 집합을 사용
- TABLE : 정형 데이터(변경 어려움)
- 기존 데이터 구조 → 새로운 데이터 구조 생성 가능
SELECT DEPTNO, ENAME,EMP.JOB,SAL,IV.AVG_SAL
FROM EMP, (SELECT JOB,ROUND(AVG(SAL)) AS AVG_SAL FROM EMP GROUP BY JOB ) IV
WHERE EMP.JOB = IV.JOB AND SAL > IV.AVG_SAL
ORDER BY DEPTNO ,SAL DESC; // 장점?
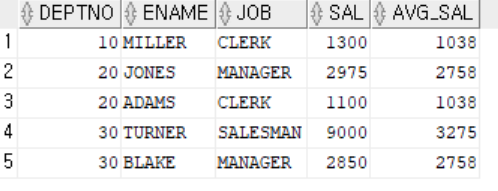
TOP-N, BOTTOM-M
- ROWNUM을 사용 → 상/하위 data 추출
- data size 많을 시 문제
SELECT *
FROM (SELECT EMPNO,ENAME,SAL FROM EMP ORDER BY SAL ASC) BM
WHERE ROWNUM <= 5;
SELECT TN.EMPNO,TN.ENAME,TN.SAL
FROM (SELECT EMPNO,ENAME,SAL FROM EMP ORDER BY SAL DESC) TN
WHERE ROWNUM < 5;
DML 연산과 SubQuery
SELECT문으로 연산 처리 → DML(INSERT, UPDATE, …) 가능
// SUBQUERY로 한번에 N개 Rows INSERT
INSERT INTO BONUS(ENAME,JOB,SAL,COMM) SELECT ENAME,JOB,SAL,COMM FROM EMP;
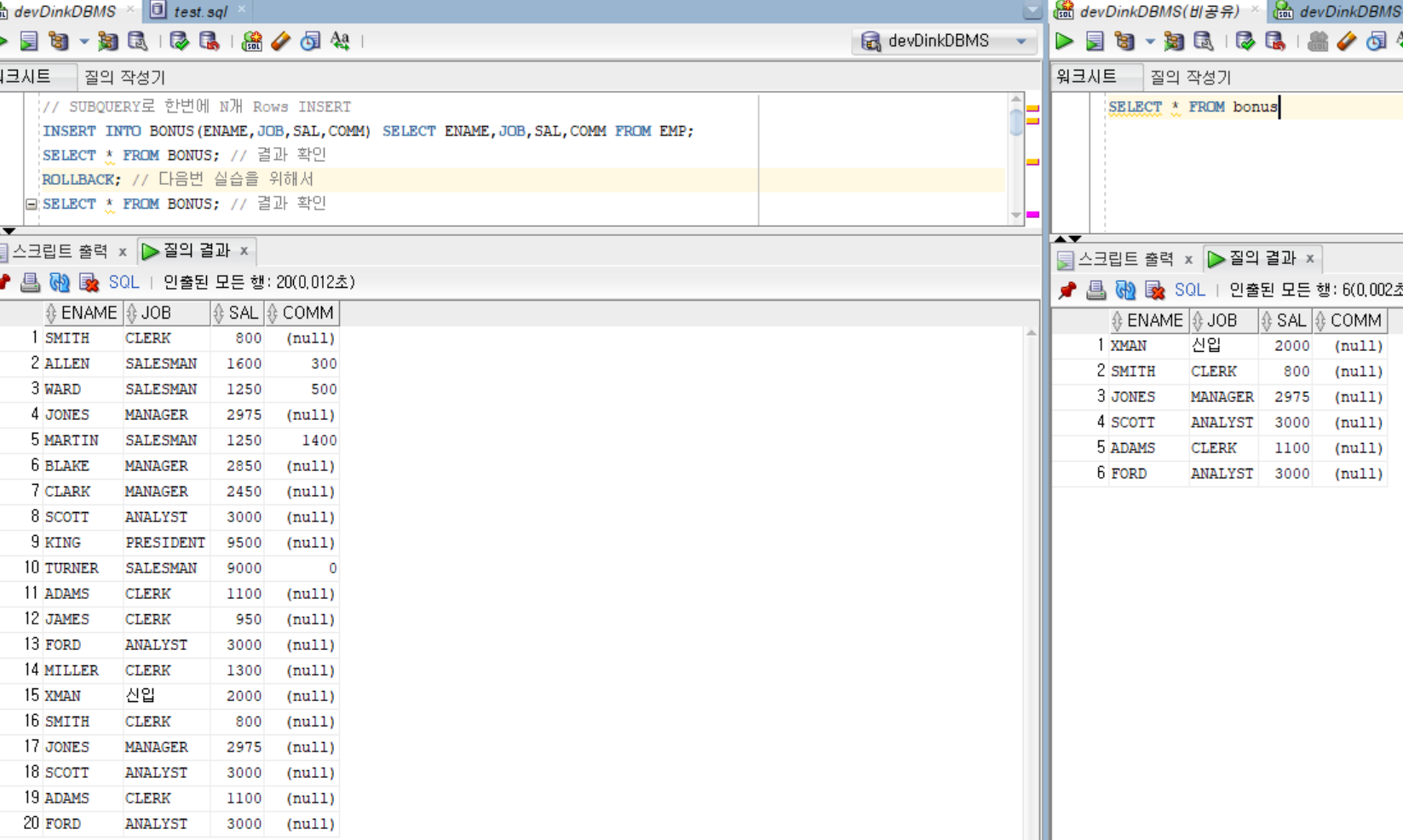
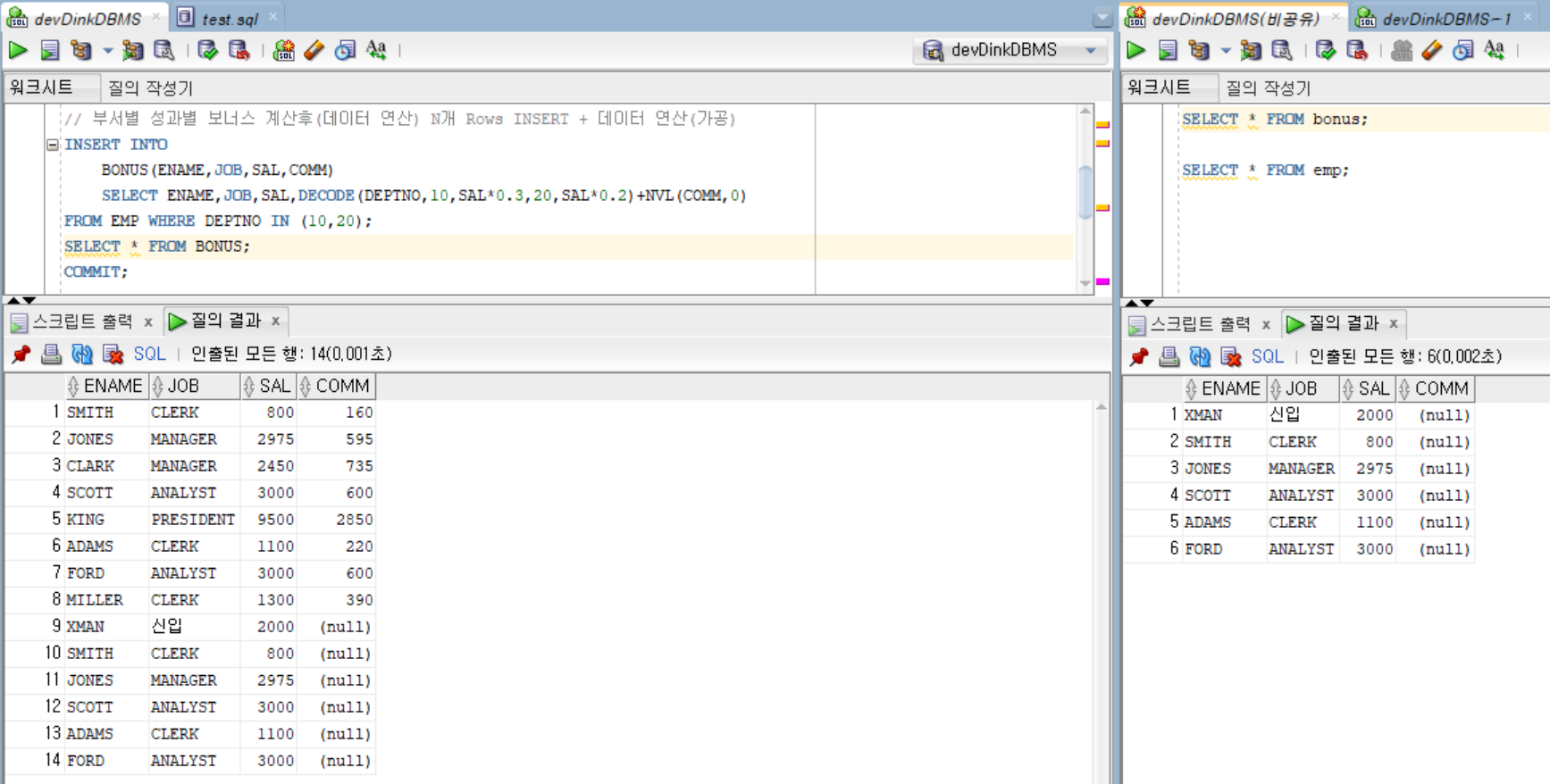
// 부서별 성과별 보너스 계산후(데이터 연산) N개 Rows INSERT + 데이터 연산(가공)
INSERT INTO
BONUS(ENAME,JOB,SAL,COMM)
SELECT ENAME,JOB,SAL,DECODE(DEPTNO,10,SAL*0.3,20,SAL*0.2)+NVL(COMM,0)
FROM EMP WHERE DEPTNO IN (10,20);
SELECT * FROM BONUS;
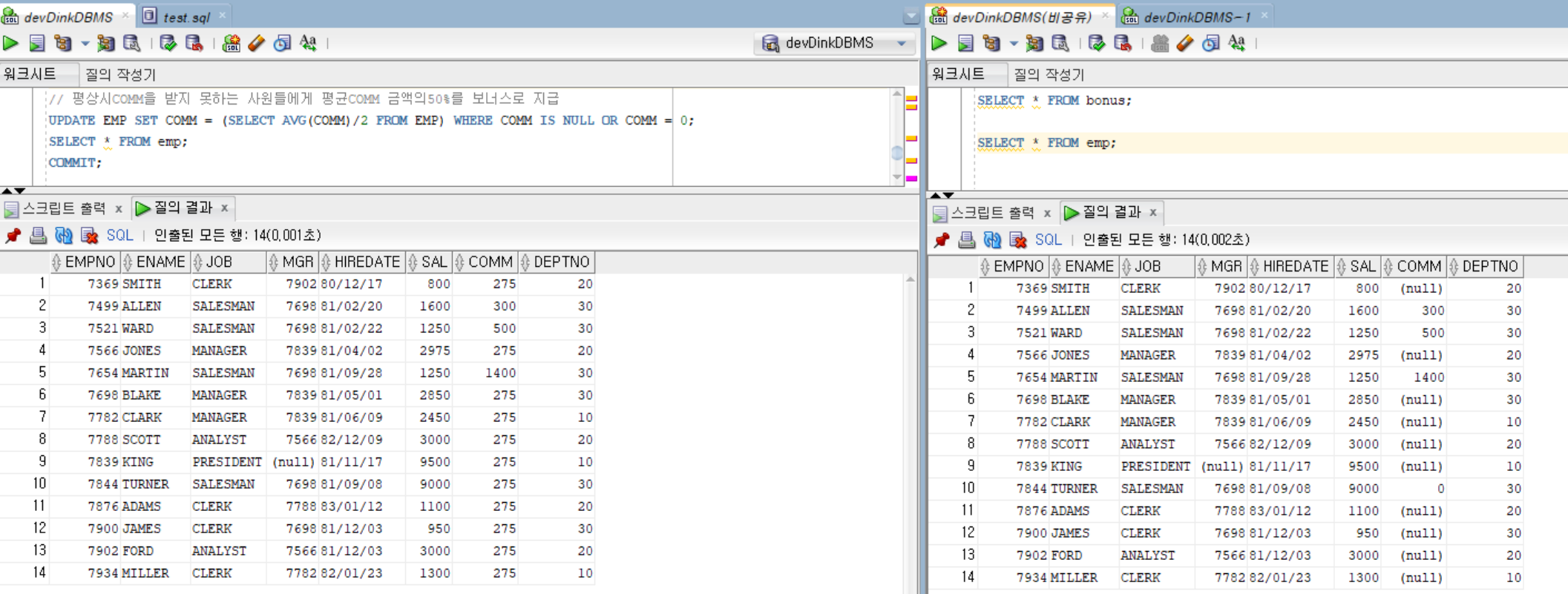
// 평상시COMM을 받지 못하는 사원들에게 평균COMM 금액의50%를 보너스로 지급
UPDATE EMP SET COMM = (SELECT AVG(COMM)/2 FROM EMP) WHERE COMM IS NULL OR COMM = 0;
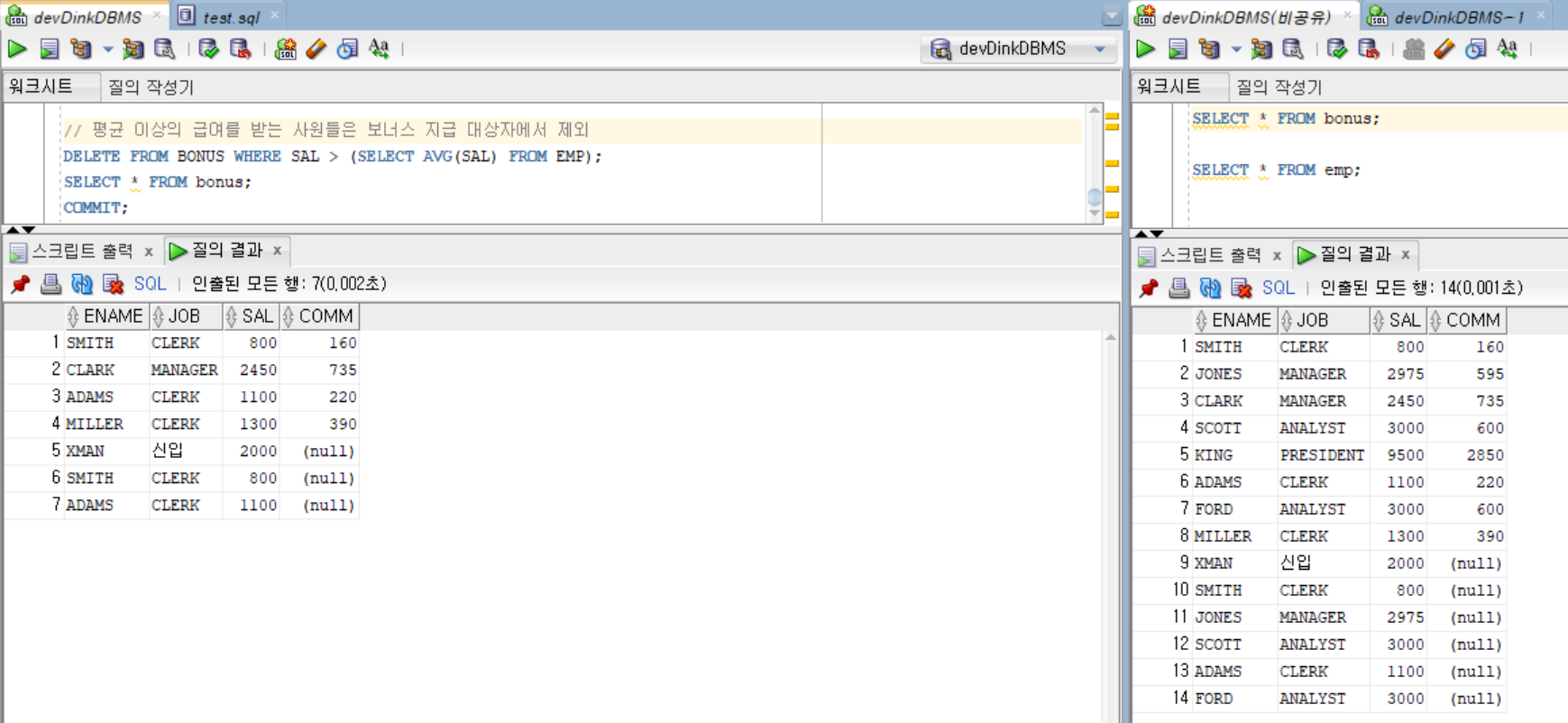
// 평균 이상의 급여를 받는 사원들은 보너스 지급 대상자에서 제외
DELETE FROM BONUS WHERE SAL > (SELECT AVG(SAL) FROM EMP);



C
Contents